본 논문은 2017 International Symposium on Computer Architecture (ISCA 2017)에 발표된 논문이다. Google에서 개발한 Tensor Processing Unit (TPU)에 관련된 내용을 포함한다. TPU는 Machine Learning (Neural Network) Application 성능 향상을 위해 제안된 가속기이다. NN에 대한 지식이 부족해서 논문 내용을 단순히 정리하는 작업을 진행하였다.
(Introduction)
본 논문에서는 Deep Neural Networks (DNNs)가 유명해진 이유로 Large Data Sets (Big Data)와 Computing Power (향상된 연산 능력) 2가지를 지목하였다. 정확히 설명하면 DNN Application들이 실행 가능해진 이유이다. DNN은 여러 개의 Layer로 구성되어 있으며, 각 Layer는 서로 네트워크로 연결되어 있다. GPU 등과 같은 높은 연산 능력을 갖춘 머신으로 네트워크 모델링을 진행한다.
NN은 크게 2가지 Phase로 구성되어 있다. 1단계는 Training (또는 Learning)이라고 하여 앞에서 말한 Layer와 네트워크를 정확하게 모델링 하는 단계이다. 2단계는 Inference (또는 Prediction)이라 하여 특정 Input에 해당하는 결과를 예측하는 단계이다. 해당 Input의 결과를 예측하기 위해 1단계에서 생성한 네트워크를 사용한다.
본 논문에 따르면 아래의 3가지 NN이 요즘 많이 사용되는 알고리즘(?)이다. (개인적으로 CNN, MLP 등과 같은 네트워크를 알고리즘이라 해야 할지 애플리케이션이라 정의를 해야 할지 잘 모르겠다)
- Multi-Layer Perceptrons (MLP): Nonlinear Function으로 구성되어 있으며, 각 Layer가 Fully Connected로 연결된 형태이다.
- Convolution Neural Networks (CNN): Nonlinear Function으로 구성되어 있으면, 특정 Layer의 부분 집합(Subset)의 Weight(결과)를 사용하여 다음 Layer로 전달하는 형태이다. CNN의 마지막 Layer의 경우 보통 Fully Connected로 연결되어 있다.
- Recurrent Neural Networks (RNN): 가장 유명한 RNN으로 Long Short-Term Memory (LSTM)이 있다. CNN과 비슷한 형태이지만, 다음 Layer로 전달하는 값을 계산하기 위해 Layer의 부분 집합의 Weight만 사용한다. LSTM의 경우 부분 집합의 모든 Weight 값을 사용하지 않고 Random(또는 다른 다양한 방법)으로 몇몇 Weight 값을 계산에서 무시하여 계산을 진행한다. (보통 Translation의 경우 앞의 단어가 뒤에 나오는 단어에 영향을 주게된다. 이러한 경우 LSTM을 사용한다)
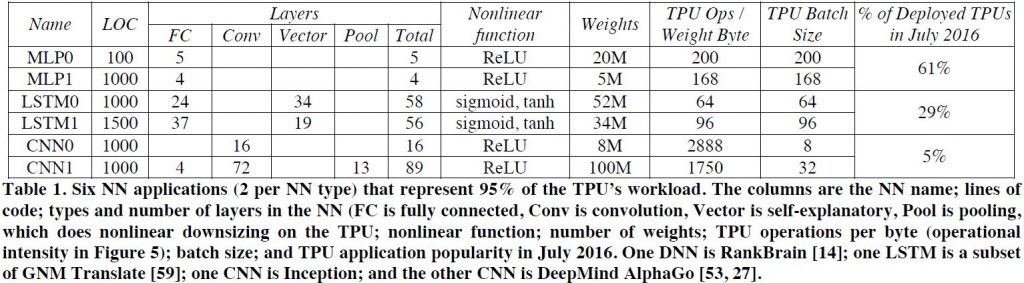 그림 1: Google Datacenter에서 실행되는 Benchmark Application 정리
그림 1: Google Datacenter에서 실행되는 Benchmark Application 정리
Google Datacenter에서 사용되는 전체 NN 애플리케이션(?) 중 위 3개의 알고리즘이 전체의 95% 정도를 차지한다. 위 알고리즘을 사용한 Benchmark의 경우 코드의 길이가 대략 100~1,500줄로 짧은 편이다. 또한, 해당 Benchmark는 User Facing Detection과 같이 빠른 Response Time을 요구한다. 그림 1은 본 논문에서 사용하는 Benchmark의 Setting을 정리한 표이다.
(TPU Origin, Architecture, Implementation, And Software)
TPU 최종 목적은 Cost-Performance를 기존 GPU 대비 10배 이상 향상하는 것이다. TPU 제작 기간 (Design, Verify, Build, Deploy)는 15개월 정도이며, TPU를 제작하게 된 계기는 2013년 이후부터 급속도로 증가하는 Voice Recognition 연산량을 감당하기 위해서이다.
TPU는 PCI/e Bus를 사용하는 Co-processor이다. TPU는 Instruction을 Fetching 하는 등의 Overhead를 제거하기 위해 Instruction을 Host Server로부터 받아서 단순히 실행하는 형태이다 (논문에서는 CPU와 Tightly 연결되어 있지 않다고 하는데 Host로부터 Instruction을 받아야 한다는 말은 생각보다 많이 Tightly Integrated 된 것 같은 기분이 든다). TPU는 전체 Inference를 연산하도록 설계되었다. 하지만, NN 네트워크의 일부 Layer만 연산하는 것도 가능하다.
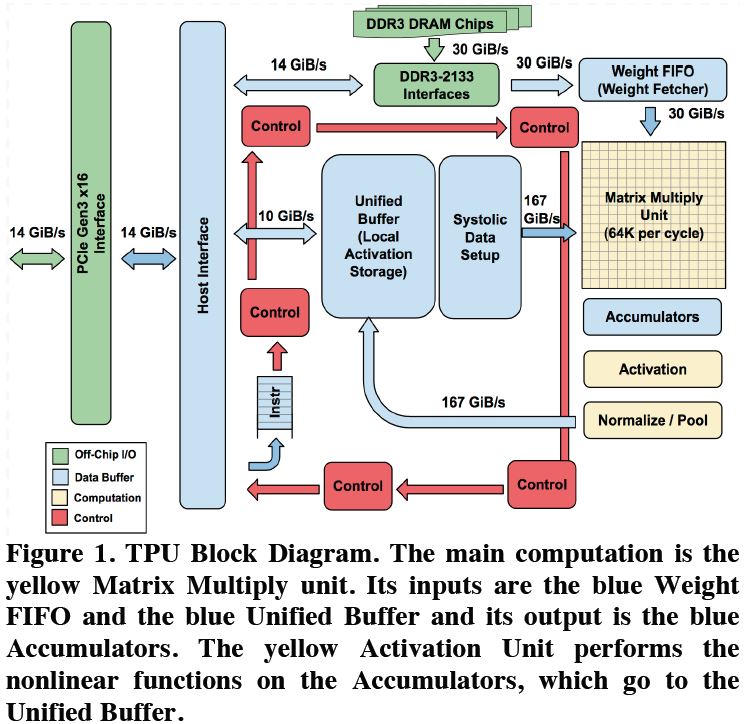 그림 2: TPU Block Diagram
그림 2: TPU Block Diagram
그림 2은 TPU Block Diagram이다. TPU의 가장 중요한 부분은 오른쪽에 있는 8-Bit Matrix Multiply Unit (MMU)이다. 해당 유닛은 8-Bit Multiply-and-Add 연산을 수행한다 (Unsigned and Signed). 한 사이클에 총 256개의 Element 연산이 수행 가능하며, 해당 유닛에서 나온 연산 결과값은 MMU 아래에 있는 Accumulator에 저장된다.
MMU 연산에 필요한 데이터 값은 Weight FIFO에서 읽어온다. 해당 Weight FIFO의 데이터 값은 Weight Memory라는 8GiB DRAM에서 읽어온다. 그림 2에서 보이는 Unified Buffer(UB)는 MMU에서 연산한 결과값을 임시로 저장하거나 CPU로부터 읽은 데이터 값을 저장한다.
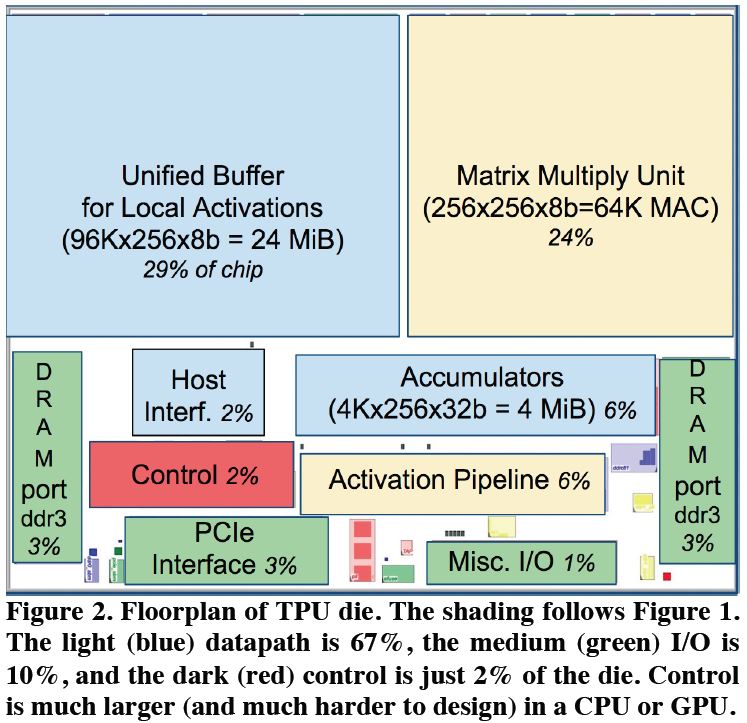 그림 3: Floorplan of TPU
그림 3: Floorplan of TPU
 그림 4: TPU Board 사진
그림 4: TPU Board 사진
그림 3는 TPU의 유닛들이 차지하는 크기를 정리한 그림이다. 그림 3에서 보듯이 MMU와 Unified Buffer가 전체 Chip의 50% 이상을 차지하고 있다. 그 외 다른 부분은 아주 작은 부분을 차지한다. 그림 4은 TPU를 Board 사진이다.
TPU 요즘 많이 사용되는 RISC(Reduced Instruction Set Computer)를 사용하지 않고 CISC(Complex Instruction set computing) 형태를 사용하고 있다. TPU는 대략 열 개(Dozen) Instruction을 지원한다. 그중 아래 5개가 TPU를 대표하는 Instruction이다.
- Read_Host_memory: Host Memory의 데이터를 UB로 복사
- Read_weight: Weight Memory의 데이터를 Weight FIFO로 복사
- MatrixMultiply/Convolve: Matrix Multiply 또는 Convolution 연산을 수행하여 Accumulator에 저장
- Activate: 활성 함수(Activation Function) 연산을 수행함. ReLU, Sigmoid, 등을 지원
- Write_Host_memory: UB에서 데이터를 Host Memory로 복사
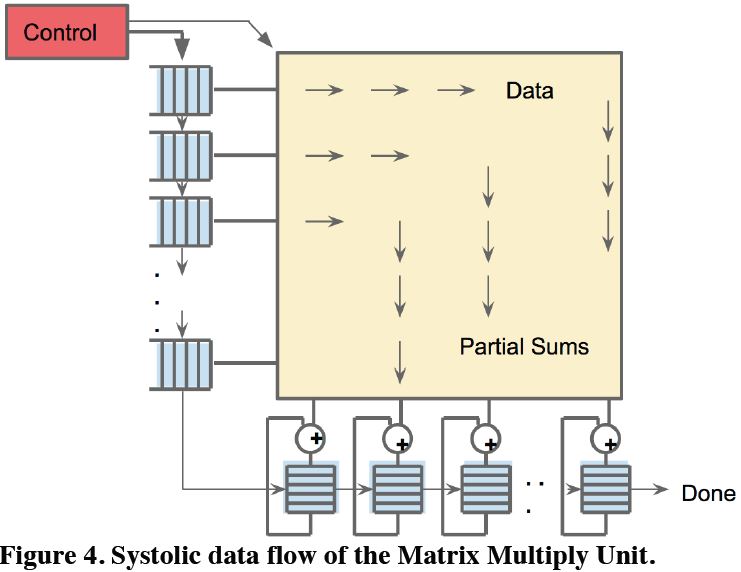 그림 5: Systolic Data Flow
그림 5: Systolic Data Flow
TPU Execution Stage는 총 4단계로 구성되어 있다. 각 Stage는 서로 다른 Instruction을 실행하며 ILP성능 향상을 목표로 한다. 또한, MMU는 Energy를 소비를 줄이기 위해 Systolic Execution 모델을 활용한다. 그림 5는 Systolic Data Flow를 보여준다.
위키피디아에 따르면 Systolic Execution(Systolic Array) 모델은 각 Execution(Node) 모듈에서 나오는 Output을 다음 Execution Unit(Node)의 Input으로 사용하는 모델이다. Systolic Execution은 때로는 MISD (Multiple Instruction Single Data)로 구분할 수도 있다.
TPU에서는 Systolic Execution 모델을 사용하여 256 Element의 Multiply-ACcumulate(MAC) 연산에 한 번에 수행한다. Correctness를 위해서 Software를 작성할 때는 Systolic Execution 모델에 대한 지식이 없어도 된다.
TPU Software Stack은 기존 CPU와 GPU와 같이 사용할 수 있도록 지원한다. TPU Software Stack은 GPU와 같이 User Space Driver와 Kernel Driver로 구성되어 있다. Kernel Driver은 메모리 관리 및 Interrupt 핸들링만 지원한다. User Space Driver은 TPU 실행, TPU에 데이터 로딩하는 순서, TPU Instruction 등을 TPU로 복사하는 등의 작업을 지원한다. TPU는 높은 성능을 위해서 모든 NN 모델 연산의 시작부터 끝까지 연산을 수행할 수 있도록 설계되었다. 하지만, NN 네트워크의 한 Layer 씩 연산 수행도 가능하다.
(CPU,GPU, And TPU Platforms (Evaluation Environment))
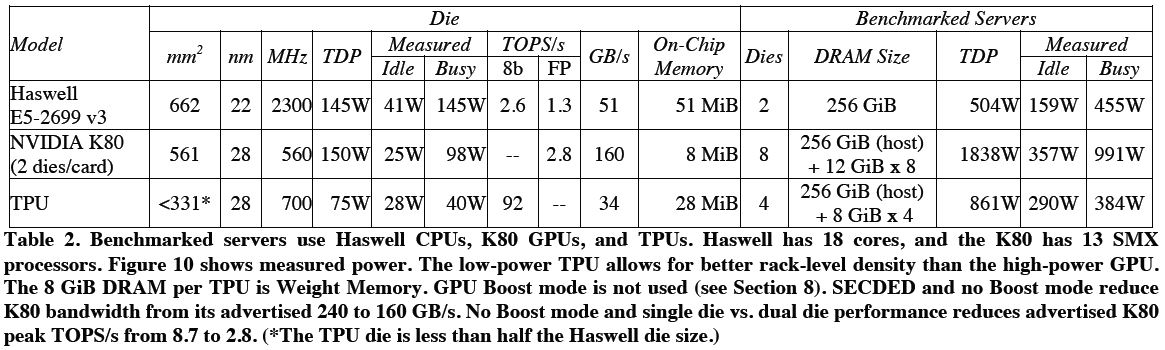 그림 6: CPU, GPU, TPU 스펙 비교
그림 6: CPU, GPU, TPU 스펙 비교
그림 6은 본 논문에서 성능 측정을 진행한 CPU, GPU, TPU의 스펙을 보여준다. CPU의 경우 2.3GHz로 동작하고 Turbo 모드는 Disable 하였다. GPU의 경우 2015년 기준으로 NN Application 연산에 가장 많이 사용되는 K80 모델을 선택하였다.
(Performance: Rooflines, Response-Time, And Throughput)
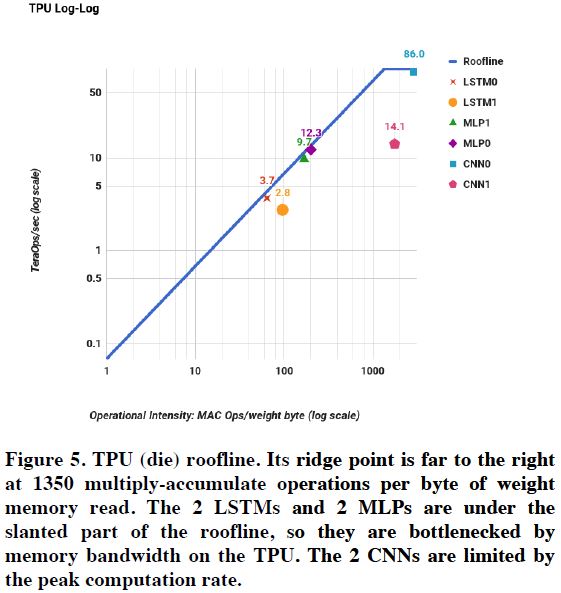 그림 7: TPU Roofline 결과
그림 7: TPU Roofline 결과
본 논문에서는 3개의 다른 Processor의 성능 분석을 위해서 Roofline Performance Model을 사용한다. Roofline Performance Model은 HPC의 성능 Bottleneck을 분석하기 위한 툴이다. 완벽하지는 않지만, Insight를 보기에는 적당하다고 판단한다. Roofline의 Y-축은 Floating-Point Operations Per Second를 의미하고, X-축은 Floating-Point Operations per DRAM Byte Accessed를 의미한다. 그림 7은 TPU의 Roofline log-log Scale 된 결과이다. 5개의 Application의 경우 Roofline에 아주 근접하게 붙어 있다. 논문에 따르면 MLP, LSTM은 Memory Bound이고, CNN은 Computation Bound이다. (개인적인 생각인데, Roofline의 제일 위에 보이는 위치에 도달하지 않으면 애플리케이션은 Memory Bound로 분류한다. 반면, CNN0와 같이 Roofline의 제일 높은 위치에 놓여있는 관계로 Compute Bound로 분류한다)
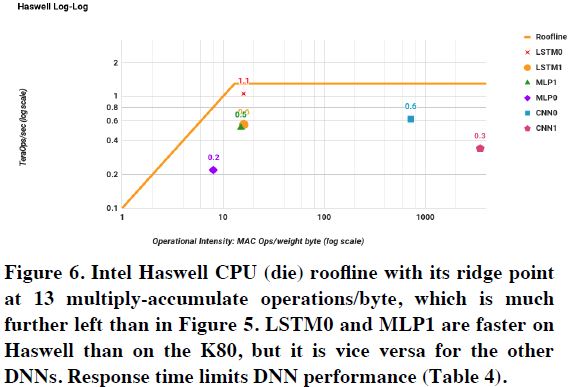 그림 8: Haswell CPU Roofline
그림 8: Haswell CPU Roofline
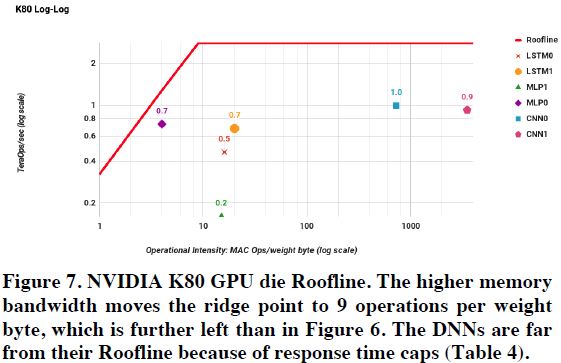 그림 9: K80 GPU Roofline
그림 9: K80 GPU Roofline
그림 8, 9는 Haswell CPU와 K80 GPU의 Roofline을 보여준다. 모든 NN Application이 Roofline 아래에 있다. 논문에서 CPU, GPU가 TPU보다 Roofline에 근접하지 않은 이유로 Response Time 때문이라고 말한다. Training의 경우 Response Time이 중요하지 않지만, Inference의 경우 Response Time이 중요하다. Inference 연산의 Response Time이 높을 경우 사용자가 실제로 Application을 사용하지 않는 문제가 발생한다.
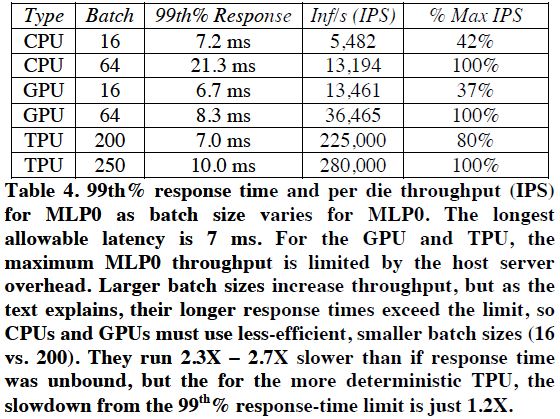 그림 10: Response Time에 따른 CPU, GPU, TPU의 IPS 성능
그림 10: Response Time에 따른 CPU, GPU, TPU의 IPS 성능
그림 10은 Response Time에 따른 CPU, GPU, TPU 성능을 비교한 표이다. Response Time을 7ms 정도로 제한할 경우 CPU, GPU는 대략 40% 정도의 IPS 성능을 보인다. 반면, TPU의 경우 최대의 80% 성능을 보인다.
 그림 11: TPU가 CPU와 Interact하는 시간 정리
그림 11: TPU가 CPU와 Interact하는 시간 정리
그림 11은 TPU와 CPU가 Interact 하는 포션을 정리한 그림이다. 해당 그림은 TPU와 CPU가 실제로 Interact 하는 경우의 시간만 측정한 결과로 CPU가 NN Application의 다른 연산을 하는 시간은 제외하였다.
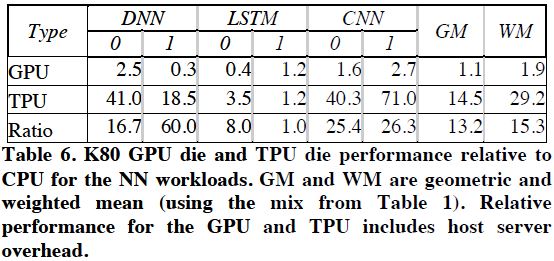 그림 12: CPU 대비 GPU, TPU의 성능 향상
그림 12: CPU 대비 GPU, TPU의 성능 향상
그림 12는 CPU 대비 GPU, TPU의 성능 향상을 정리한 표이다. 해당 결과는 CPU의 모든 Overhead를 포함한 결과이다. TPU는 CPU 대비 대략 14.5배 그리고 GPU 대비 대략 13.2배의 성능 향상을 보인다. (해당 결과에서 약간 놀라운 점은 GPU가 CPU 대비 좋은 성능을 보이지 못한다는 부분이다)
(Cost-Performance, TCO, And Performance/Watt)
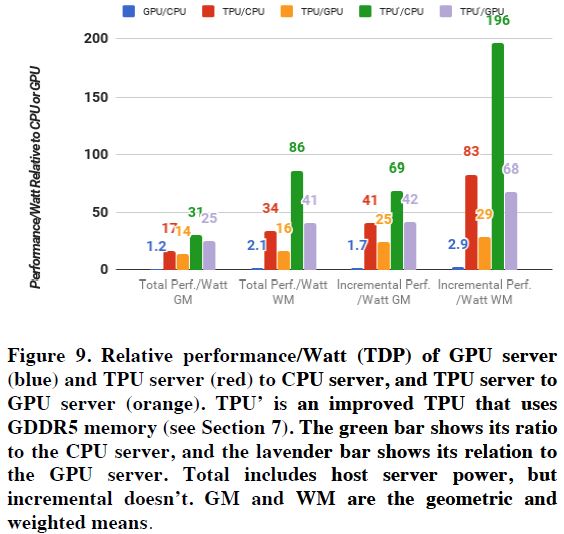 그림 13: CPU, GPU, TPU의 Performance/Watt Metric 결과
그림 13: CPU, GPU, TPU의 Performance/Watt Metric 결과
Datacenter에서 가장 많이 사용되는 Cost Metric은 TCO(Total Cost of Ownership)이다. 하지만, 서버 가격을 공개할 수 없는 관계로 Performance/Watt Metric 결과만 공개하였다. 그림 13는 CPU, GPU, TPU의 Performance/Watt Metric 결과이다. Total은 CPU의 전력 사용량을 포함한 결과이며, Incremental의 경우 CPU의 전력 사용량을 제외한 결과이다. TPU는 CPU 대비 대략 17-34배 높은 Performance/Watt 결과를 보이며, GPU 대비 대략 14-16배 높은 결과를 보인다.
(Energy Proportionality)
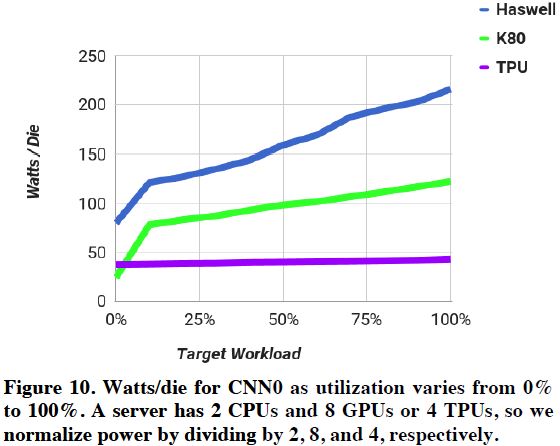 그림 14: CPU, GPU, TPU의 Energy Proportionality 성능
그림 14: CPU, GPU, TPU의 Energy Proportionality 성능
그림 14은 CPU, GPU, TPU의 Workload의 Load에 따른 파워 사용량을 측정한 결과이다. TPU가 Energy Proportionality 성능이 가장 나쁘다. TPU에 10% 정도를 Load를 가하면, 100% Load가 가했을 때 때 대비 88%의 파워를 소모한다. 반면 CPU와 GPU의 경우 56%, 66% 정도의 파워만 소비한다. 하지만, 전체적인 파워 소비는 TPU가 압도적으로 낮은 것을 확인할 수 있다. TPU는 대략 40w 정도의 파워만 사용한다.
추가적으로, TPU를 사용하면 GPU를 사용하는 경우 대비 CPU에 더 많은 Load가 가해진다고 한다. 그 이유로 TPU가 더 많은 연산을 빨리 수행하기 때문에 CPU가 해야 하는 일이 많아진다.
(Evaluation of Alternative TPU Designs)
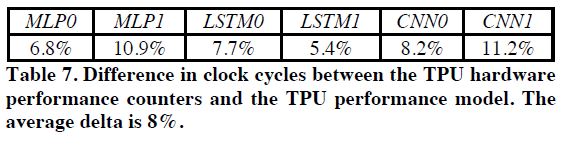 그림 15: TPU Performance Model과 TPU의 성능 차이
그림 15: TPU Performance Model과 TPU의 성능 차이
본 논문에서는 하드웨어 변화에 따른 성능 변화를 분석하기 위해서 TPU Performance Model을 설계했다. 해당 논문에서 설계한 TPU Performance Model은 실제 TPU와 대략 10% 정도의 에러가 존재한다. 그림 15는 TPU Performance Model과 실제 TPU의 성능 차이를 정리한 표이다.
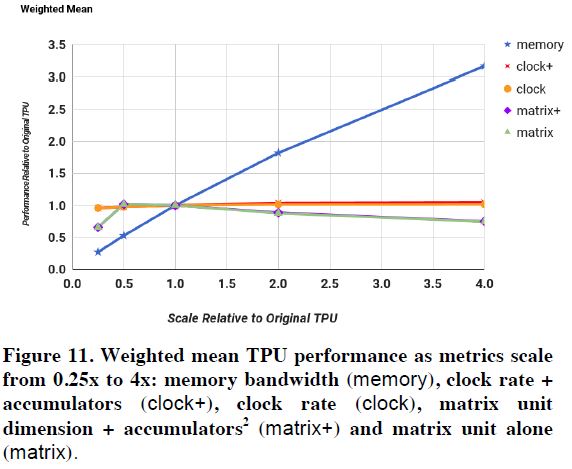 그림 16: Clock 속도, Memory Bandwidth, Matrix Unit에 따른 성능 변화
그림 16: Clock 속도, Memory Bandwidth, Matrix Unit에 따른 성능 변화
그림 16은 Clock 속도, Memory Bandwidth, Matrix Unit 개수 등을 달리하면서 성능 변화를 분석한 결과이다. 다른 부분은 큰 변화가 없는 반면 Memory Bandwidth에 따른 성능 변화는 최대 3배 정도 차이가 발생한다. 가장 큰 이유는 대부분의 NN Benchmark Application이 Memory Bound로 인해 성능 병목현상이 발생하기 때문이다. 본 논문에서는 TPU의 DRAM을 GDDR5로 변경하면 최대 4배의 성능 향상을 얻을 수 있다고 한다.
CNN의 경우 Compute Bound라서 실제로 Clock 속도를 변경하면 약 2배 정도의 성능 향상이 가능하다고 한다. 하지만, MLP, LSTM Application의 경우 Clock 속도에 따른 큰 성능 변화가 없어서 평균값은 거의 변하지 않는다.
 그림 17: Unified Buffer(UB) 사용량
그림 17: Unified Buffer(UB) 사용량
그림 16은 TPU에서 Unified Buffer의 메모리 사용량을 정리한 표이다. 최대 14MiB정도의 메모리만 사용하는 것을 확인할 수 있다.
(Discussion)
본 논문에서 다양한 주제(저자 생각)를 Fallacy(틀린 생각)와 Pitfall(위험)로 나누어서 저자의 생각을 정리하였다.
Fallacy: NN inference applications in datacenters value throughput as much as response time.
위 주장은 틀린 주장이라 한다. Datacenter에서 NN Inference는 Response Time이 훨씬 중요하다고 한다. 사용자는 Response Time이 느릴 경우 NN Inference Application을 사용하지 않는다고 한다.
Fallacy: The K80 GPU architecture is a good match to NN inference
역시 틀린 주장이라 한다. 본 논문에서 NN Inference Application은 Response Time이 더 중요하기 때문에 K80과 같이 Throughput Oriented 된 Architecture는 적합하지 않다고 주장한다.
Pitfall: Architects neglected important NN tasks
Architecture들이 더 다양한 NN 네트워크 가속을 위해 집중할 필요가 있다고 주장한다. 2016년 ISCA에 발표된 NN 가속기 논문중 2개의 Article을 제외하면, 나머지 논문은 모두 CNN 가속에만 집중하였다. 하지만 Google Datacenter의 경우 CNN Application의 연산량이 5% 정도밖에 되지 않는다고 한다.
Pitfall: For NN hardware, Inferences Per Second (IPS) is an inaccurate summary performance metric
TPU의 경우 MLP와 CNN의 IPS 차이가 최대 75배 정도 발생한다. 결과적으로 IPS로 여러 개의 성능 비교를 하는 데 적합하지 않을 수도 있다.
Fallacy: The K80 GPU results would be much better if Boost mode were enabled
위 주장은 틀린 주장이라 한다. Boost 모드를 사용하여 실험한 결과 대략 1.4배의 성능 향상과 1.1배의 Performance/Watt 성능 향상이 있었다고 한다.
Fallacy: CPU and GPU results would be similar to the TPU if we used them more efficiently or compared to newer versions
위 주장도 틀린 주장이라 한다. CPU에서 8-Bit 연산을 수행하면 대략 3.5배의 성능 향상이 존재했다. 2015년 초기에는 더 괜찮은 GPU가 없었다고 이야기한다. (이 부분의 주장은 다소 엉성하다는 생각이 든다. 최근 GPU는 16-Bit 연산도 지원을 한다)
Pitfall: Performance counters added as an afterthought for NN hardware
TPU는 총 106개의 Performance Counter가 내장되어 있다. 더 많은 Performance Counter를 추가하기를 원한다고 한다.
Fallacy: After two years of software tunning, the only path left to increase TPU performance is hardware upgrades.
위 주장은 틀렸다고 한다. Developer와 Compiler가 더 좋은 코드를 작성할 경우 더 높은 성능이 가능할 수도 있다고 주장한다.
Pitfall: Being ignorant of architecture history when designing a domain-specific architecture
History-Aware Architects Could Have Competitive Edge. (Computer Architecture 역사를 알면 경쟁에 우위를 가질 수 있다)
(Related Work)
해당 부문에서 관련 논문으로 언급한 논문을 정리하였다.
- Fathom: reference workloads for modern deep learning methods
- The Handbook of Brain Theory and Neural Networks
- Training Neural Networks with Spert-II. Chapter 11 in Parallel Architectures for Artificial Networks: Paradigms and Implementations
- Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
- High Performance Hardware for Machine Learning
- A VLSI architecture for highperformance, low-cost, on-chip learning
- Special-purpose digital hardware for neural networks: An architectural survey
- If I could only design one circuit…: technical perspective
- Toward accelerating deep learning at scale using specialized hardware in the datacenter
- A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services
- Convolution engine: balancing efficiency & flexibility in specialized computing
- Design of a 1st Generation Neurocomputer
(결론: 개인적인 생각임)
ISCA 2017에서 발표한 논문을 정리해보았다. 개인적으로 TPU는 단순히 엄청나게 많은 MMU와 UB를 가진 Processor이다. 어쩌면, NN 네트워크에 연산은 더 이상 CPU와 GPU와 같은 General Purpose Processor에서는 실행할 필요가 없을 수도 있다고 생각한다.
출처
- In-Datacenter Performance Analysis of A Tensor Processing Unit (ISCA 2017)
- https://en.wikipedia.org/wiki/Systolic_array