 그림 1: Volta GPU Concept 사진
그림 1: Volta GPU Concept 사진
2017년 Annual GPU Technology Conference에서 Volta GPU가 최초로 공개되었다. 2013년에 처음으로 NVIDIA에서 Volta GPU Architecture 이름을 공개하였다. 공개 당시 Maxwell 다음 Volta GPU architecture가 공개될 예정이었지만, 실제로는 Maxwell, Pascal, Volta 순서대로 GPU Architecture가 공개되었다. 현재 공개된 정보에 따르면 Volta GPU는 Highend Computing 특히 Machine Learning에 최적화된 제품인 듯하다.
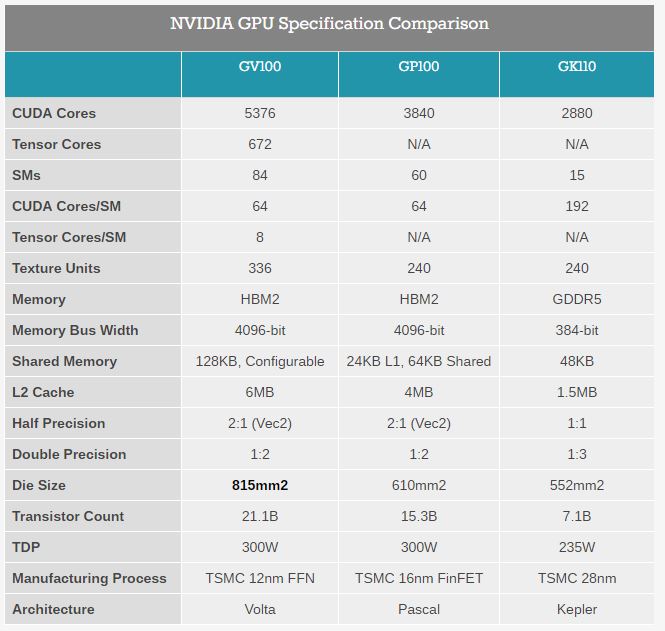 그림 2: GV100, GP100, GK110의 Spec 비교표
그림 2: GV100, GP100, GK110의 Spec 비교표
공개된 Volta GPU의 칩 이름은 GV100이다. 위 사진은 GK110, GP100, GV100의 Spec을 비교한 표이다. 가장 충격적인 부분은 Die 크기이다. Die 크기가 무려 815㎟로 GP100보다도 200㎟ 이상 커진 것을 확인할 수 있다 (대략 33% 정도 Die 크기가 증가하였다. 개인적으로 칩 수율이 궁금하다). GV100은 12nm “FFN”을 사용하였다 (FFN의 N은 NVIDIA의 N을 의미하는 것이라 한다).
GV100은 기존 GP100과 상당한 차이가 있다. GV100에서는 Tensor Core, Thread Execution, Thread Scheduling, Core Layout, Memory Controller 등에서 기존 GP100과 많은 차이가 존재한다. 아직 많은 부분이 공개되지 않아서 추후 White Paper가 공개되면 모든 차이를 상세히 정리할 계획이다.
GV100은 최대 84개의 Streaming Multiprocessor (SM)을 가지고 있다. 각 SM은 최대 64개의 Core를 가지고 있다. 결과적으로 총 5,376 (64 x 86)의 FP32 CUDA Core를 내장하고 있다. 또한, 2,688개의 FP64 (Double Floating Point) 연산 코어를 내장하고 있다.
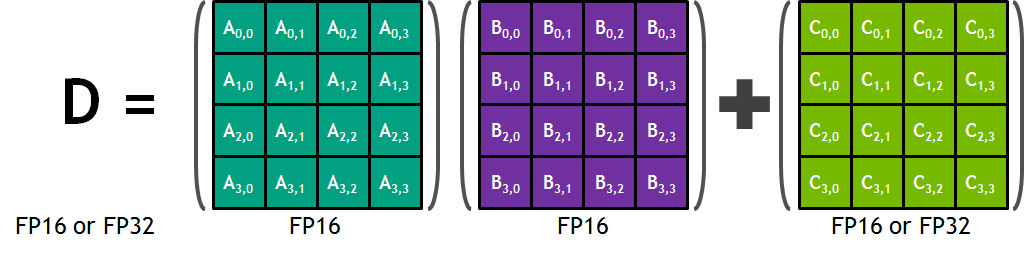 그림 3: Tensor Core의 연산 예제
그림 3: Tensor Core의 연산 예제
GV100에서 Tensor Core라는 새로운 코어가 각 SM에 추가되었다. Tensor Core는 Machine Learning 연산 성능을 향상하기 위해 추가된 듯하다. Tensor Core는 4 x 4 Matrix 연산을 수행할 수 있으며 Fused Multiply Add (FMA) (A x B + C)을 하기 위해 제작되었다고 한다. 위 그림은 Tensor Core가 연산을 수행하는 예제이다. 두 개의 FP16 (Half Precision Floating Point) 값은 곱한 후 FP16 또는 FP32 (Single Precision Floating Point)와 더하는 연산을 수행 후 최종적으로 FP16 또는 FP32 형태의 Output을 출력한다. 각 SM의 Tensor Core의 경우 1 clock에 64개의 FMA 연산이 가능하다.
 그림 4: GV100 Streaming Multiprocessor (SM) 그림
그림 4: GV100 Streaming Multiprocessor (SM) 그림
위 그림은 GV100의 SM을 묘사한 그림이다. 각 SM은 4개의 Texture Units을 가지고 있으면 128KB의 L1 Data Cache/Shared Memory를 내장하고 있다. GV100의 L1 Data Cache와 Shared Memory는 GP100의 L1/Shared Memory와 달리 다시 Reconfigurable 하다.
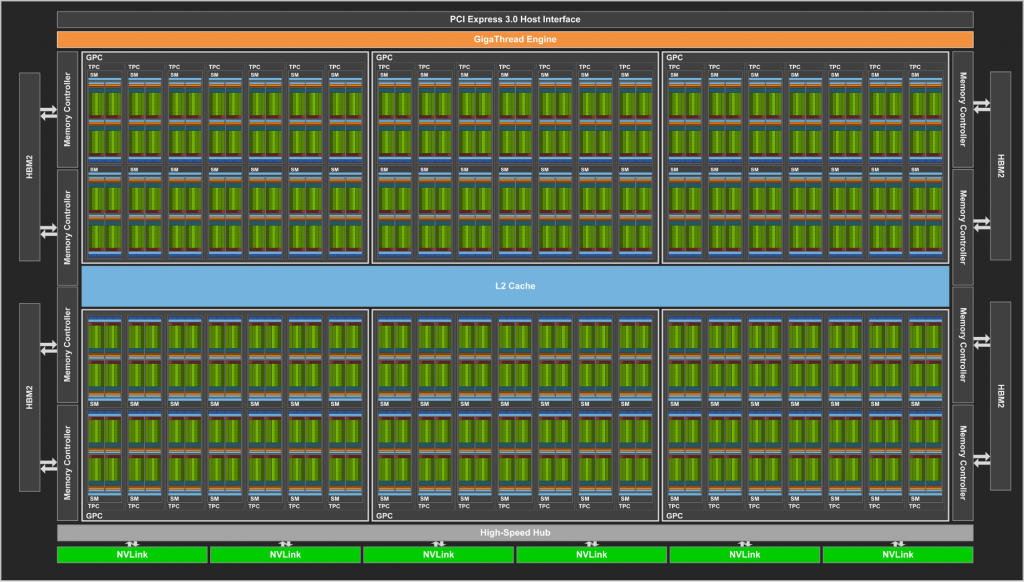 그림 5: GV100의 SM, TPC, GPC 구성 그림
그림 5: GV100의 SM, TPC, GPC 구성 그림
위 그림은 GV100의 전체를 묘사한 그림이다. GV100의 경우 2개의 SM이 하나의 TPC를 구성한다. 다시 7개의 TPC가 하나의 GPC를 구성하여 총 6개의 GPC로 구성된 형태이다.
또한, GV100에서는 NVLink 2가 추가되었다. 기존의 NVLink 보다 높은 메모리 대역폭을 (20GB/sec –> 25GB/sec) 가지며 더 많은 NVLink (4개 –> 2개)을 연결할 수 있다. 또한, CPU의 메모리와 Cache Coherence를 유지한다고 한다.
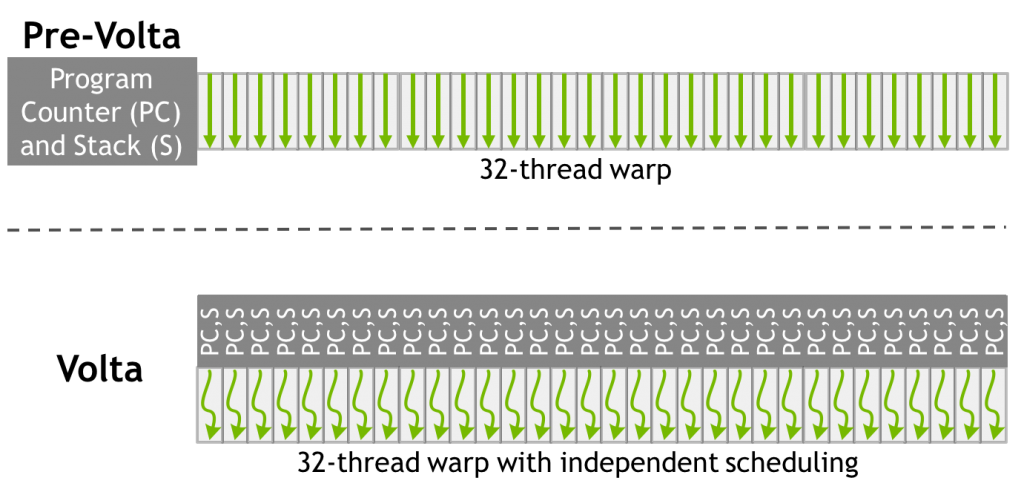 그림 6: GV100의 Thread Execution 모델
그림 6: GV100의 Thread Execution 모델
최종적으로 Volta에서 가장 큰 변화는 SIMT 형태의 Execution 모델이 변경된 것이다. 기존과 달리 1개의 Warp의 32개의 Thread가 각기 다른 Control Flow를 가질 수 있다는 것이다. 위 그림은 Volta의 Execution 모델을 묘사한 그림이다. 한 개의 Warp의 32개 Thread가 각각의 PC (Program Counter)를 가지고 있는 것을 확인할 수 있다. 개인적으로 GPU의 가장 큰 장점이 단순한 Control Logic이었다고 알고 있는데 이렇게 하면 더 단순 Control Logic이 단순하다고 말하기 어려운 것 같다. GPU가 CPU와 비슷해지듯 하다.
아직 많은 부분이 공개되지 않아 현재 아래 출처에서 읽은 내용을 짧게 정리하였다. 추후 더 공개되는 자료는 읽고 공부해서 정리할 계획이다.
출처
- https://www.anandtech.com/show/11367/nvidia-volta-unveiled-gv100-gpu-and-tesla-v100-accelerator-announced