목차: Series 1 – Index + Methodology (Link)
이전 글: Series 6 – It’s All Random (Link)
다음 글: Series 8 – Metal (Link)
Diffuse Material을 계산하기 위해서 작성한 CPU Color Function(함수)는 Recursive Function(재귀 함수)을 사용한다. 해당 코드를 CUDA로 변경하면 Stack Overflow가 발생할 확률이 매우 높다. 출처 3에 따르면 CUDA의 경우 최대 24번의 Recursive Function 호출이 가능하다고 한다. Diffuse Material CPU 코드에서는 Recursive Function Depth의 제한이 없다. 하지만, 바로 다음 장에서 작성하는 Metal CPU 코드에서는 Recursive Depth를 50회로 제한한다. CUDA로 작성한 코드에서 Stack Overflow를 방지하기 위해서 Depth를 제한하는 코드를 이번장에서 먼저 작성한다.
MK: 성능 비교를 위해서 CPU 코드 역시 Depth 부분을 미리 작성하여서 성능을 비교하였다.
출처 3에 따르면 CUDA는 최대 24번의 Recursive 호출이 가능하다. 다시 말해서 50회로 Depth를 제한하여도 CUDA로 작성한 코드의 경우 높은 확률로 Stack Overflow가 발생한다. 항상 Color 함수가 50번의 Recursive 호출을 하지 않기 때문에 정상적으로 동작하는(?) 경우가 있을 수도 있다. 문제를 해결하기 위해서 Recursive Function을 Iteration(Loop)으로 변경하여서 CUDA 코드를 작성한다. 아래 코드는 Color 함수를 수정한 Main 코드이다.
코드 1: Main 파일 코드
#include <fstream>
#include "mkRay.h"
#include <time.h>
#include "mkSphere.h"
#include "mkHitablelist.h"
#include <float.h>
#include <curand_kernel.h>
#include "mkCamera.h"
using namespace std;
//MK: FB 사이즈
int nx = 1200;
int ny = 600;
int ns = 100;
// limited version of checkCudaErrors from helper_cuda.h in CUDA examples
//MK: #val은 val 전체를 String으로 Return 함 (출처 3)
#define checkCudaErrors(val) check_cuda( (val), #val, __FILE__, __LINE__ )
//MK: Error 위치를 파악하기 위해서 사용
void check_cuda(cudaError_t result, char const *const func, const char *const file, int const line) {
if (result) {
cerr << "MK: CUDA ERROR = " << static_cast<unsigned int>(result) << " at " << file << ":" << line << " '" << func << "' \n";
// Make sure we call CUDA Device Reset before exiting
cudaDeviceReset();
exit(99);
}
}
__global__ void mkCreateWorld(hitable **dList, hitable **dWorld, camera **dCamera){
if(threadIdx.x == 0 && blockIdx.x == 0){
*(dList) = new sphere(vec3(0, 0, -1), 0.5);
*(dList + 1) = new sphere(vec3(0, -100.5, -1), 100);
*dWorld = new hitableList(dList, 2);
*dCamera = new camera();
}
}
//MK: (코드 1-2) Random 하게 Vector을 생성하기 위한 코드
#define RANDVEC3 vec3(curand_uniform(localRandState), curand_uniform(localRandState), curand_uniform(localRandState))
//MK: (코드 1-3) Unit Sphere의 Random한 포인터를 생성하기 위한 코드
__device__ vec3 randomInUnitSphere(curandState *localRandState){
vec3 p;
do{
p = 2.0f * RANDVEC3 - vec3(1.0, 1.0, 1.0);
} while (p.squared_length() >= 1.0f);
return p;
}
//MK: (코드 1-1) Recurisve 함수를 Loop을 사용하도록 변경함
__device__ vec3 color(const ray &r, hitable **dWorld, curandState *localRandState){
ray curRay = r;
float curAttenuation = 1.0f;
for(int i = 0; i < 50; i++){
hitRecord rec;
if((*dWorld)->hit(curRay, 0.001f, FLT_MAX, rec)){
vec3 target = rec.p + rec.normal + randomInUnitSphere(localRandState);
curAttenuation *= 0.5f;
curRay = ray(rec.p, target-rec.p);
}
else{
vec3 unitDirection = unitVector(curRay.direction());
float t = 0.5f * (unitDirection.y() + 1.0f);
vec3 c = (1.0f - t) * vec3(1.0, 1.0, 1.0) + t * vec3(0.5, 0.7, 1.0);
return curAttenuation * c;
}
}
return vec3(0.0, 0.0, 0.0);
}
__global__ void mkRender(vec3 *fb, int max_x, int max_y, int num_sample, camera **cam, hitable **dWorld) {
//MK: Pixel 위치 계산을 위해 ThreadId, BlockId를 사용함
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = threadIdx.y + blockIdx.y * blockDim.y;
//MK: 계산된 Pixel 위치가 FB사이즈 보다 크면 연산을 수행하지 않음
if((i >= max_x) || (j >= max_y)){
return;
}
//MK: FB Pixel 값 계산
int pixel_index = j*max_x + i;
curandState rand_state;
//curand_init(1984, pixel_index, 0, &rand_state);
curand_init(pixel_index, 0, 0, &rand_state);
vec3 col(0, 0, 0);
for(int s = 0; s < num_sample; s++){
float u = float(i + curand_uniform(&rand_state))/float(max_x);
float v = float(j + curand_uniform(&rand_state))/float(max_y);
ray r = (*cam)->get_ray(u, v);
col += color(r, dWorld, &rand_state);
}
fb[pixel_index] = col/float(num_sample);
}
__global__ void mkFreeWorld(hitable **dList, hitable **dWorld, camera **dCamera){
if(threadIdx.x == 0 && blockIdx.x == 0){
delete *(dList);
delete *(dList + 1);
delete *dWorld;
delete *dCamera;
}
}
int main() {
//MK: Thread Block 사이즈
int tx = 8;
int ty = 8;
cout << "MK: Rendering a " << nx << "x" << ny << " Image ";
cout << "MK: in " << tx << "x" << ty << " Thread Blocks.\n";
clock_t start, stop;
start = clock();
int num_pixels = nx*ny;
size_t fb_size = 3*num_pixels*sizeof(float);
//MK: FB 메모리 할당 (cudaMallocManaged 는 Unitifed Memory를 사용 할 수 있도록 함)
//MK: 필요에 따라 CPU/GPU에서 GPU/CPU로 데이터를 복사함
vec3 *fb;
checkCudaErrors(cudaMallocManaged((void **)&fb, fb_size));
hitable **dList;
hitable **dWorld;
camera **dCamera;
checkCudaErrors(cudaMalloc((void **) &dList, 2 * sizeof(hitable *)));
checkCudaErrors(cudaMalloc((void **) &dWorld, sizeof(hitable *)));
checkCudaErrors(cudaMalloc((void **) &dCamera, sizeof(camera *)));
mkCreateWorld<<<1, 1>>>(dList, dWorld, dCamera);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaDeviceSynchronize());
//MK: GPU (CUDA) 연산을 위해서 Thread Block, Grid 사이즈 결정
dim3 blocks(nx/tx+1,ny/ty+1);
dim3 threads(tx,ty);
//MK: CUDA 함수 호출
mkRender<<<blocks, threads>>>(fb, nx, ny, ns, dCamera, dWorld);
checkCudaErrors(cudaGetLastError());
//MK: CUDA 연산이 완료되길 기다림
checkCudaErrors(cudaDeviceSynchronize());
//MK: 연산 시간과 끝 부분을 계산하여서 연산 시간을 측정함
//MK: CPU 코드와 동일하게 결과를 파일에 작성
string fileName = "Ch7_gpu.ppm";
ofstream writeFile(fileName.data());
if(writeFile.is_open()){
writeFile.flush();
writeFile << "P3\n" << nx << " " << ny << "\n255\n";
for (int j = ny-1; j >= 0; j--) {
for (int i = 0; i < nx; i++) {
size_t pixel_index = j*nx + i;
int ir = int(255.99 * fb[pixel_index].r());
int ig = int(255.99 * fb[pixel_index].g());
int ib = int(255.99 * fb[pixel_index].b());
writeFile << ir << " " << ig << " " << ib << "\n";
}
}
writeFile.close();
}
mkFreeWorld<<<1, 1>>>(dList, dWorld, dCamera);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaFree(dList));
checkCudaErrors(cudaFree(dWorld));
checkCudaErrors(cudaFree(fb));
checkCudaErrors(cudaFree(dCamera));
//MK: 연산 시간과 끝 부분을 계산하여서 연산 시간을 측정함
stop = clock();
double timer_seconds = ((double)(stop - start)) / CLOCKS_PER_SEC;
cout << "MK: GPU (CUDA) Took " << timer_seconds << " Seconds.\n";
return 0;
}코드 1-1은 Recursive Function을 Iteration(Loop) 형태로 변경한 코드이다. Recursive Function과 비슷하게 50번 안에 최종 색상이 결정되면 Loop을 종료한다. 위 파일을 컴파일해서 실행하면 아래 그림 1의 결과 이미지를 확인 할 수 있다.

성능 측정 결과
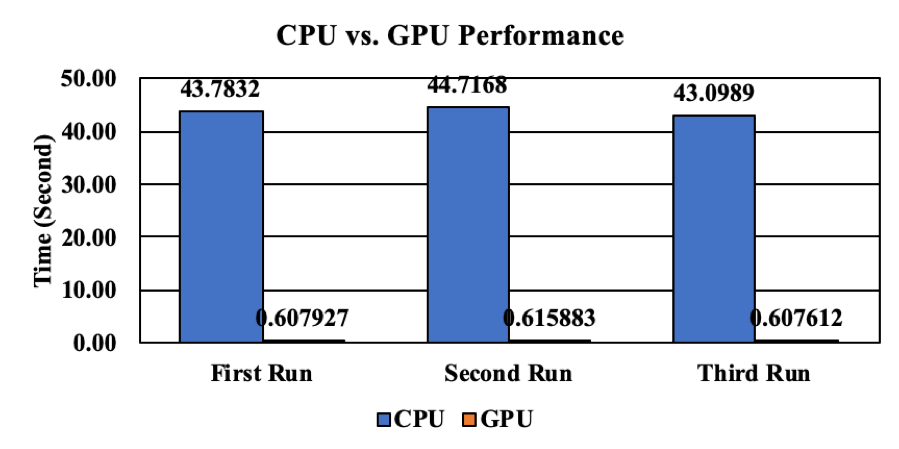
그림 2는 CPU/GPU 성능을 비교한 결과이다. GPU는 CPU 대비 대략 72배 정도 빠른 성능을 보인다. 앞 장에서는 AA 연산량으로 인해서 CPU와 GPU 성능 차이가 크게 발생하였다. 이번 장에서는 AA 연산에 추가로 색상값 결정을 위해서 Recursive Function(CUDA의 경우 Loop을 사용)을 사용해서 연산량이 많이 증가하였다. 아마도 이로 인해서 CPU와 GPU의 성능 차이가 더 많이 발생한 것으로 판단된다.
출처
- https://devblogs.nvidia.com/accelerated-ray-tracing-cuda/
- http://www.realtimerendering.com/raytracing/Ray%20Tracing%20in%20a%20Weekend.pdf
- https://stackoverflow.com/questions/27757256/cuda-recursion-depth
- https://github.com/mkblog-cokr/CudaRTSeries