목차: [Series 01] Index & Overview (Link)
다음 글: [Series 02] Detect System Capabilities (Link)
목차 (Index)
- [Series 01] Index & Overview (Link)
- [Series 02] TBD (Link)
Purpose & Objective?
CUDA를 사용해서 GPU 병렬화 프로그래밍을 작성해본 적이 있다. CPU 역시 GPU와 비슷하게 SIMD 연산(SSE/AVX/AVX2/AVX-512)을 지원한다. 개인적으로 AVX에 대해서 찾아보던 중 정리가 잘 된 글이 있어서 정리하게 되었다. 지금부터 작성하는 AVX 글은 출처 1에서 발취한 내용이다. 작성하는 과정에서 추가로 Reference를 찾게 되면 출처를 추가할 예정이다.
What is Streaming SIMD Extensions (SSE) and Advanced Vector Extensions (AVX)?
90년대는 CPU 성능 향상을 위해서 CPU Clock을 높이는 방식으로 CPU를 설계하였다. 하지만, 2000년(최근?)에 파워/발열 문제로 인해서 더 이상 Clock을 향상하는 방법으로는 CPU 성능을 높이지 못하게 되었다. 그래서 CPU 설계자(Designer)들은 CPU 성능 향상을 위해 아래의 3가지 방법을 사용하게 되었다.
- Multi-Cores: CPU Core를 개수를 늘려서 성능 향상을 시도하였다. 여러 개의 Application/Program을 다른 Core에서 연산을 수행함으로 성능 향상을 시도하였다. 물론 Multi-Thread를 사용해서 하나의 Application/Program 성능 향상도 가능하다.
- Vectorization (SIMD/SIMT): Vector 연산을 추가하였다. Single Instruction Multiple Data (SIMD) 형태의 연산을 추가하여서 성능 향상을 시도하였다. 이 부분은 Application/Program을 제작하는 과정에서 성능 향상을 시도하는 방법이다.
- Instruction Level Parallelism (ILP): ILP를 상승시키는 방식으로 성능 향상을 시도하였다. 이 부분은 Application/Program에서 Dependency가 없는 Instruction을 찾아서 동시에 실행시키는 방법이다.
SSE/AVX은 2번째 방법에 해당한다. SSE/AVX는 Vector 연산을 위한 Instruction Set이다. SSE는 1999에 처음 추가되었다. 그 후 계속 발전해서 SSE1에서 SSE4.2까지 추가되었다. AVX는 2011에 추가되었고, AVX2는 2013년에 추가되었다. 2016년에는 AVX-512도 추가되었다.
SSE, AVX(AVX2), AVX-512의 가장 큰 차이는 Register 크기이다. SSE는 128-Bit Register를 사용해서 연산을 수행하고, AVX(AVX2)는 256-Bit Register를 사용하고, AVX-512는 512-Bit Register를 사용한다. 간단히 설명하면 SSE는 4개의 32-Bit 연산을 지원하고, AVX(AVX2)는 8개의 32-Bit 연산을 지원하고, AVX-512는 16개의 32-Bit 연산을 지원한다. 16-Bit 연산을 수행하는 경우 위 숫자의 2배 개수의 연산을 한 번에 수행할 수 있다.
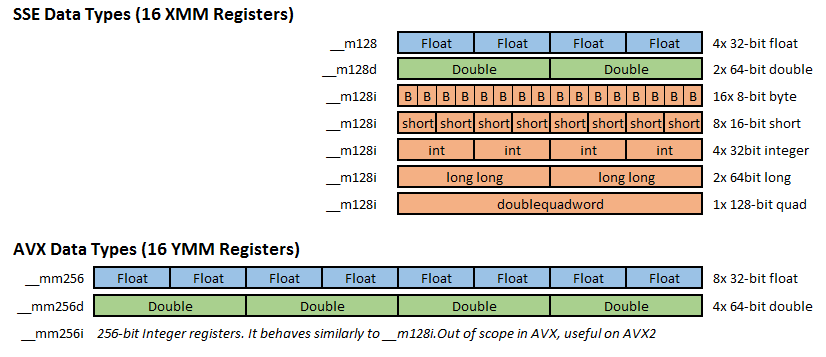
위 그림 1은 SSE, AVX Register에 값이 저장되는 방법을 보여준다. SSE, AVX(AVX2)는 16개의 Register로 구성되어 있다고 한다.
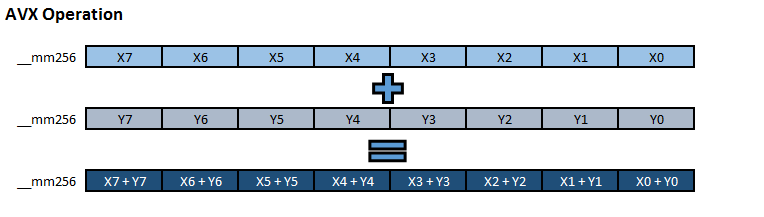
위 그림 2는 2개의 AVX Register를 사용해서 ADD 연산을 수행하는 방법을 보여준다. 각 Register는 8개의 32-Bit Floating (또는 Integer) 값으로 구성되어 있다. AVX2에서 8개의 32-Bit Integer 값을 저장할 수 있도록 추가된 것으로 판단된다. 하나의 ADD Instruction(명령어)을 사용해서 8개의 연산을 한번에 계산하고 있다. 이렇게 하나의 Instruction을 사용해서 여러 개의 Data를 계산하는 방식을 Single Instruction Multiple Data (SIMD)라고 한다. GPU의 Single Instruction Multiple Thread (SIMT)와 거의 유사한 방법이다.
출처 (References)
- https://www.codingame.com/playgrounds/283/sse-avx-vectorization/what-is-sse-and-avx
- https://ko.wikipedia.org/wiki/%EC%8A%A4%ED%8A%B8%EB%A6%AC%EB%B0%8D_SIMD_%ED%99%95%EC%9E%A5
- https://ko.wikipedia.org/wiki/%EA%B3%A0%EA%B8%89_%EB%B2%A1%ED%84%B0_%ED%99%95%EC%9E%A5