Midgard GPUs
ARM에서 최근에 만든 Bifrost GPU 이전 모델인 Midgard에 대해서 짧게 정리해보았다. Exynos 5250 (2012년 추정)에서 첫 세대 Midgard를 사용하였고, 마지막으로 3세대 Midgard가 Exynos 8890 (2016년 추정)에 생산되었다 (출처 1, 2). Midgard GPU는 Mali-T600, Mali-T700, Mali-T800 시리즈가 있다. Midgard GPU는 요즘 GPU의 기본인 Unified Shader Core를 사용한다. Unified Shader Core란 Vertex Shader 연산, Fragment Shader 연산, Compute Kernel 연산 등 모든 종류의 연산 코드를 한 Processor가 다 실행하는 것을 의미한다. Midgard GPU의 경우 생산하는 업체(삼성, 화웨이 등)에 따라 코어 수를 달리 할 수 있다. 제일 최근에 발표된 Mali-T800 (이것도 오래된 제품임)의 경우 최소 1개 Core에서 최대 16개 Core까지 설계할 수 있다.
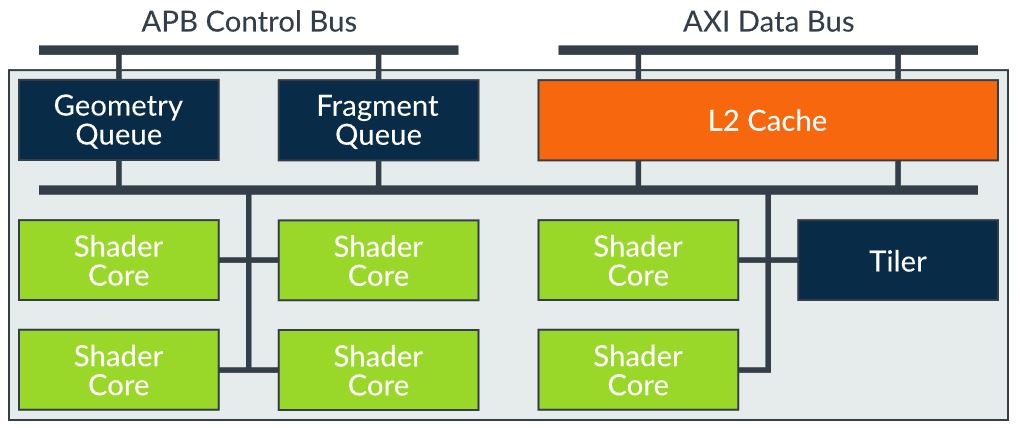 그림 1: Midgard GPU 구조 (출처 3)
그림 1: Midgard GPU 구조 (출처 3)
그림1은 6개의 Core를 가진 Midgard GPU이다. 그림에 표시된 L2 Cache의 경우 모든 코어가 공유하고 있다. L2 Cache의 크기 또한 제조업체에 따라 달리 설계 가능하다. 이와 더불어
L2 Cache에서 External Memory로 연결하는 메모리 Port 역시 제조업체에 따라 설계를 달리 할 수 있다. 하지만, 1개의 Core가 32 Bit Read/Write 연산을 1 사이클에 실행 가능하도록 설계하는 것을 추천한다. 다시 말해서 8개의 Core로 구성된 Midgard GPU의 경우 256 Bit 메모리 연결 포트를 추천한다는 의미이다.
Work Issue: Midgard GPU
개인적으로 이 부분이 중요하다고 생각한다. 중요하다고 생각했던 이유는 Vertex Shader 연산과 Fragment Shader 연산의 병렬적으로 실행되는지 궁금했는데 여기서 어느 정도 답을 해준 것 같다.
Application 단에서 Render Pass가 정의되면, 각 Render Pass는 2개의 독립된 Workload로 나누어서 Scheduling 한다. 하나의 Workload는 Geometry 관련 연산이다. 다른 하나는 Fragment 관련 연산이다. Tile-based Rendering을 지원하는 Mali의 경우, 모든 Geometry 연산이 마무리되어야 Fragment 연산이 가능하다. Geometry 연산이 완료되면, Tile List가 생성된다 (위 그림을 보면 Tiler라는 구조가 존재한다. 아마도 Geometry 연산이 완료되면, 해당 결과를 저장하고, Tiler가 Tile List를 생성하는 것 같다). 이렇게 Tile List가 생성되면 Fragment 연산을 수행할 수 있다.
Mali Midgard의 경우 두 개의 Queue를 사용하여 Geometry 연산 (Vertex 연산을 의미하는 것 같음), Fragment 연산을 따로 Scheduling 할 수 있는 것 같다. 결과적으로 하나의 GPU는 서로 다른 Render Pass에 존재하는 Geometry 연산과 Fragment 연산을 동시에 수행할 수 있다. Single Render Pass의 각 Workload는 병렬성이 아주 뛰어나서 (Nearly Always Large and Highly Parallelizable), GPU Hardware가 아주 작은 단위로 나누어서 Shaded Core에 일을 분배한다.
Shader Core: Midgard GPU
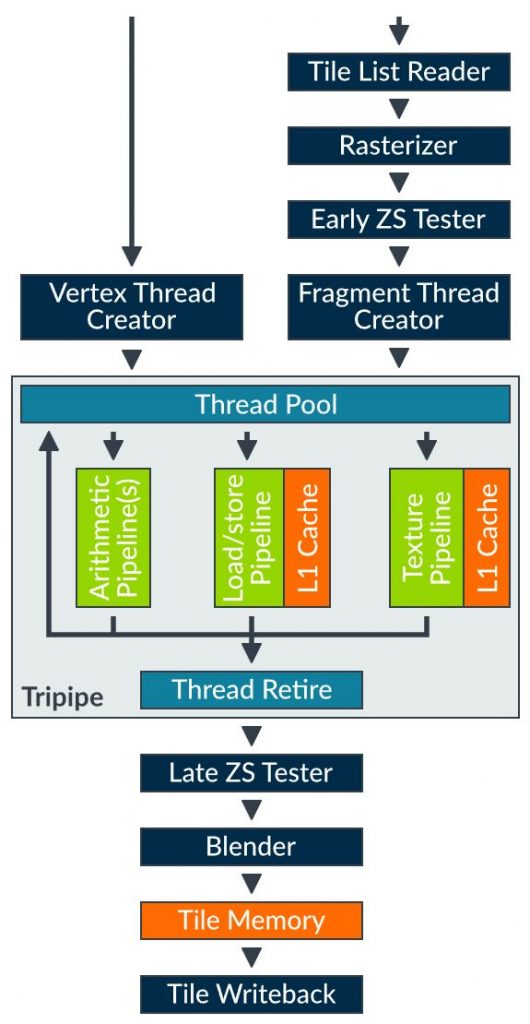 그림 2: Midgard Shader Core 구조 (출처 3)
그림 2: Midgard Shader Core 구조 (출처 3)
그림 2는 Midgard Shader Core 구조이다. Midgard Shader Core은 Fixed Function Hardware Block과 Programmable 연산 코어 Tripipe로 구성되어 있다. Fixed Function Hardware Block의 경우 Shader Operation 연산을 수행하기 위한 준비를 하거나, Rasterizing, Depth Test, Blending, 결과를 Write 하는 등의 작업을 수행한다. 기존의 CPU는 하나의 Thread를 실행하도록 설계되어있다. 반면, Programmable Core (Tripipe)는 수백 개의 Thread를 동시에 실행할 수 있는 구조로 되어 있다. 이렇게 많은 Thread를 동시에 실행하여 Cache 미스와 메모리 Loading으로 인한 Latency를 Hiding 할 수 있다. 이건 요즘 GPU의 기본적인 구조이다.
The Tripipe: Programmable Core
Tripipe 코어는 크게 3가지 연산(?)장치를 가지고 있다.
- Arithmetic Pipeline (A-Pipe): 128 Bit Quad-Word Register를 사용하여 SIMD (Single Instruction Multiple Data) 연산을 지원한다. A-Pipe의 경우 4개의 32 Bit FP/INT 연산, 8개의 16 Bit FP/INT 연산, 16개의 8 Bit INT 연산을 지원한다.
- Texture Pipeline (T-Pipe): Texture 관련 메모리 Load/Store 연산을 수행하는 유닛이다. 한 개의 Texel을 매 사이클 Loading 할 수 있도록 설계되었으나, 아래 그림에 표시된 Texture의 경우 더 오랜 시간이 걸린다. Trilinear Filter + 3D Format을 가진 Texture의 경우 4배의 시간이 걸린다.
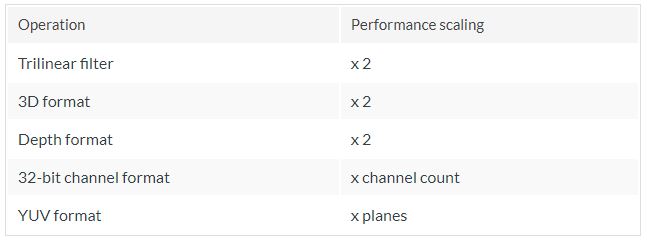 그림 3: Texture Format에 따른 Delay 시간 (출처 3)
그림 3: Texture Format에 따른 Delay 시간 (출처 3)
- Load/Store Pipeline (LS-Pipe): Texture와 관련되어 있지 않다. Pointer-based Memory Access, Buffer Access, Varying Interpolation, Atomics, imageLoad(), imageStore()의 메모리 관련 연산을 수행한다. Wide Vector 크기 (128Bit로 추정됨)의 메모리를 한 사이클에 Loading 할 수 있다. 이는 “highp” vec4를 한 Cycle에 로딩 가능하다는 의미이다.
Early and Late ZS Testing: Midgard GPU
개인적으로 아주 궁금했던 부분인데 상세한 설명이 없다. 시간이 나면 Early/Late Depth/Stencil(ZS) Testing에 대해서 정리할 계획이다. Early ZS Testing이란 Fragment Shader 연산 전에 ZS 결과를 테스트하여 필요 없다고 판단되는 Fragment(Pixel)는 Fragment 관련 연산을 수행하지 않는 것이다 (그래서 어떻게 그걸 한다는 건지는 잘 모르겠다). Late ZS Testing의 경우 Fragment Shader 연산이 완료 후 ZS 테스트를 수행하는 것이다. Depth/Stencil 값을 예측할 수 없으면 무조건 Late ZS Testing을 하게 된다. 가능하다면 Early ZS Testing을 통해서 불필요한 연산을 최소화하는 것이 좋다.
출처
- https://en.wikipedia.org/wiki/Mali_(GPU)
- https://en.wikipedia.org/wiki/Exynos
- https://developer.arm.com/graphics/developer-guides/the-midgard-shader-core