중요: 항상 그렇지만 이번 글을 특히 이해하지 못하는 부분이 많았다.
Bifrost GPUs
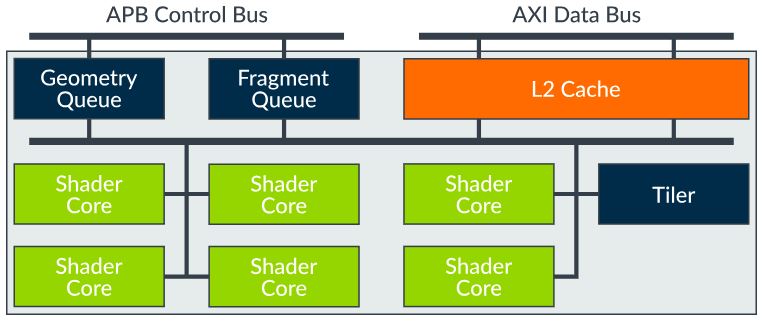 그림 1: Bifrost GPU 구조 (출처 2)
그림 1: Bifrost GPU 구조 (출처 2)
글을 쓰는 현시점에 사용되고 있는 GPU Architecture이다. 2016년 Exynos 7872를 시작으로 최근 Kirin 980에도 사용되었다 (출처1). Mali-G30, Mali-G50, Mali-G70이 Bifrost를 사용한 GPU이다. 위 그림1은 Bifrost GPU Architecture이다. 기본적인 구조는 앞서 작성한 Midgard GPU와 거의 같다. 변경된 부분에 대해서만 정리하였다.
Shader Core: Bifrost GPU
Midgard GPU와 비슷하게 Bifrost GPU도 역시 Fixed-function Hardware와 Programming Core로 구성되어 있다. 기존에 Tripipe라는 이름으로 Programming Core를 정의하였는데, Bifrost에서는 단순히 Execution Core (EC)라고 이름하였다. Bifrost GPU에서 Programming Core가 가장 큰 영역을 차지한다.
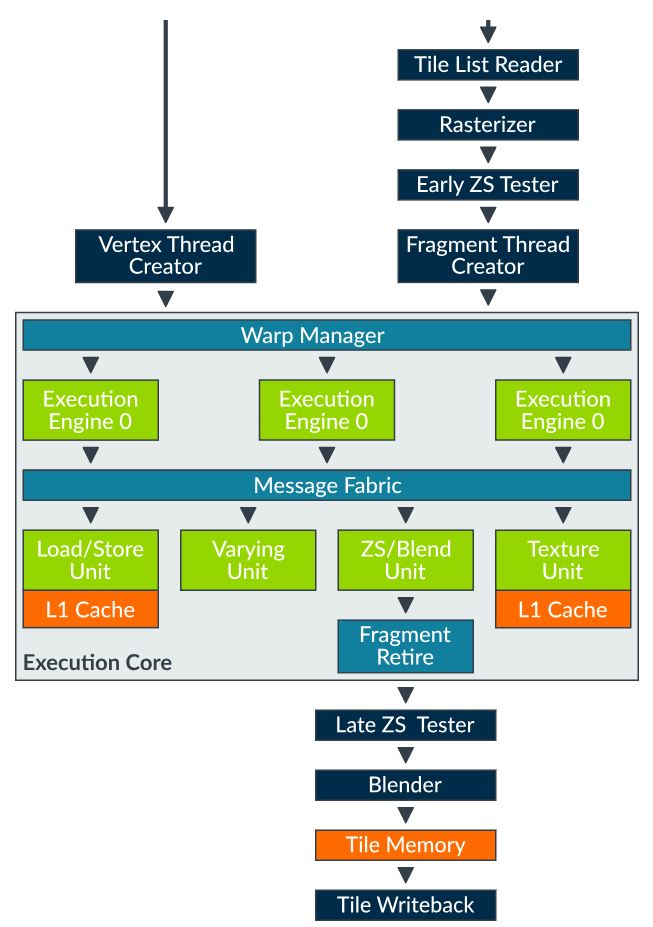 그림 2: Bifrost Shader Core 구조 (출처 2)
그림 2: Bifrost Shader Core 구조 (출처 2)
그림 2은 Bifrost Shader Core 구조이다. Programmable EC는 한 개 이상의 Execution Engine (EE) 로 구성되어 있다. Mali-G71의 경우 3개의 EE를 가진다. Bifrost Shader은 크게 2가지 크기로 구성할 수 있다. 작은 Shader의 경우 매 Cycle에 1개의 Texture Sample을 읽을 수 있고, 1 Fragment의 Blending 연산을 수행하며, 1개의 Pixel을 Write 할 수 있다. 큰 Shader의 경우 앞에 작성된 3개의 연산에 대해서 매 Cycle에 2개의 연산을 수행할 수 있다.
Thread State: Register File
NVIDIA GPU와 유사한 형태로 변경된 것 같다. 각 Shader Core는 큰 Register File을 포함하여 많은 Thread를 한 번에 실행할 수 있다. 각 Thread가 32개의 Register만 사용하면 Scheduler가 지원하는 최대 Thread가 동시에 실행된다. 32개 이상을 쓰게 되면 실행 가능한 Thread 수가 감소하게 된다. 각 Thread 당 최대 사용 가능한 Register 개수는 64개이다.
추가로 아래의 내용 설명이 있는데 정확한 의미를 파악하지 못하겠다.
- The size of the per-draw call fast constant storage, used for storing OpenGL ES uniforms and Vulkan push constants, has also been increased to 512 bytes per draw call.
Arithmetic Processing
아마도 이 부분이 가장 많이 변경된 것 같다. 기존의 Midgard GPU의 경우 Single Instruction Multiple Date (SIMD) 형태로 연산을 하였다. Bifrost의 경우 Single Instruction Multiple Thread (SIMT) 형태로 바뀌었다. 출처에 따르면 해당 연산을 Warp-based Vectorization Scheme이라고 정의하였다.
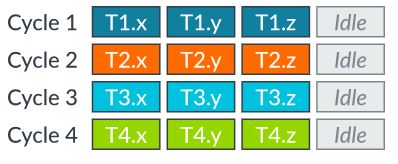 그림 3: SIMD (Vector) 연산 방법 (출처 2)
그림 3: SIMD (Vector) 연산 방법 (출처 2)
 그림 4: SIMT 연산 방법 (출처 2)
그림 4: SIMT 연산 방법 (출처 2)
그림 3는 기존 Midgard GPU의 SIMD 연산 방법을 보여준다. 그림 4은 Bifrost GPU의 SIMT 연산 방법을 보여준다. 위 그림과 같이 vec3 연산을 수행하는 경우 SIMT 연산 방식이 더 효율적이다. 당연한 이야기이지만 vec4 연산을 수행하는 경우 SIMD와 SIMT 연산 시간의 차이가 없다. 하지만, 개인적인 견해로는 SIMT형태가 아마도 더 복잡한 Control Logic을 가질 것 같다.
추가로 초창기 Bifrost의 경우 4-wide Warp를 지원하였으나, 최근에 생산되는 GPU의 경우 8-wide Warp를 지원한다. 4-wide Warp의 경우 하나의 Pixel 연산을 한 번에 한다고 하고, 8-wide Warp의 경우 두 개의 Pixel 연산을 한 번에 한다고 한다. 이 부분의 정확한 의도를 잘 모르겠다 (4-wide 이면 128 Byte 연산을 한번에 하는 것인데 왜 이게 하나의 Pixel을 의미하는지 모르겠다). 또한, Mobile Device의 경우 전력/성능 효율이 중요하기 때문에 16/8 Bit 연산을 지원한다. Midgard GPU와 같이 2개, 4개의 16 Bit, 8 Bit 연산을 지원한다.
Load Store Unit
Midgard의 LS-Pipe와 거의 같다. 성능 최적화 기법이 2가지 있어서 작성해보았다.
- Use vector loads and stores in each thread
- Access sequential address ranges across the threads in a warp
거의 당연한 이야기이다. Vector 형태로 Thread가 데이터를 Loading 하면 Memory가 Prefetch 되는 효과가 있어서 Cache 성능이 향상 될 것이다. 이와 더불어 NVIDIA GPU와 같이 동시에 실행되는 Thread (한 Warp)가 연속적인 메모리 영역을 Access 하는 경우 메모리 Access 횟수가 줄어든다. 비슷한 개념이 아마도 Memory Coalescing일 것이다. 이 부분은 따로 정리해두었다.
Varying Unit
Dedicated Fixed-function Unit이다. Arithmetic Units와 같이 Warp Vectorization을 사용한다. 여기가 난해한데 설명에 따르면 매 Cycle 당 32 Bits 단위로 Interpolate 연산을 수행한다고 한다. 설명에 따르면 mediump (fp16) vec4의 경우 2 Cycle의 연산 시간이 필요하다고 한다. highp (FP32) vec4 보다 2배 빠른 성능이다. 그럼 Warp에 4개의 Thread가 있고, 한개의 Pixel 크기는 보통 32 Bit이다. 그럼 Interpolate 연산을 수행하면 총 실행시간이 4 Cycle이라는 계산이 나온다. 그러면 실제 Arithmetic Unit 성능에 비하면 턱없이 느린 성능이 아닌지 궁금하다.
Texture Unit
역시 Midgard의 T-Pipe와 거의 같다. 기본적으로 한 개 또는 두 개의 Bilinear Filtered Texel을 로딩할 수 있다. 하지만 다른 포맷의 경우 조금씩 Delay가 더 발생한다. 아래 그림 5와 6에서 Delay 값을 보여준다.
 그림 5: Mali-G71, Mali-G72 Texture 연산 Delay 시간 (출처 2)
그림 5: Mali-G71, Mali-G72 Texture 연산 Delay 시간 (출처 2)
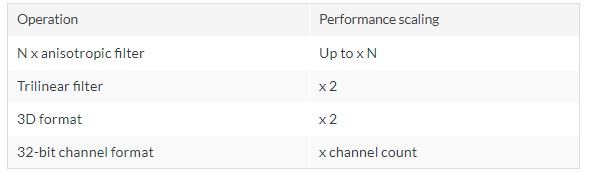 그림 6: 나머지 다른 Product Texture 연산 Delay 시간 (출처 2)
그림 6: 나머지 다른 Product Texture 연산 Delay 시간 (출처 2)
추가로 아래 정보가 포함되어 있는데 아직 그래픽에서 Texture 형태를 정확하게 파악하지 못하여서 이해를 거의 하지 못하였다.
- Do you know that 2x anisotropic filtering significantly improves image quality compared to trilinear filtering, in particular improving primitives which are almost tangential to the view plane, but is often faster than trilinear because the filtering will revert back to making a reduced number of samples whenever primitive projection in screen space is close to isotropic. Secondly it introduces optimized YUV filtering performance, allowing single cycle throughput for bilinear filtered samples irrespective of the number of input planes used to store the image data in memory. This significantly improves the performance of many applications importing camera and video streams, which commonly use semi-planar or fully planar YUV encodings.
ZS & Blend Unit
ZS Unit과 Blend Unit은 Tile-memory에 Access 하기 위한 로직이다. 정확한 설명이 없는데, 그림 2를 보면 Fragment Retire 이후에 Late ZS Tester과 Blender Fixed Function Block이 존재한다. 아마도 Blending을 하지 않으면 ZS Tester 이후 Tile Memory에 Write 하는 것 같고, Blending 연산을 수행하는 경우 Blender 연산 후 Write를 한다는 의미인 것 같다.
Blender (Blend Unit)은 매 Cycle에 1개 또는 2개의 Fragment 결괏값을 메모리에 Write할 수 있다. Mali GPU의 경우 Fast Multi-Sample Anti-Aliasing (MSAA)를 지원하여 Full Rate Blending 연산이 수행된다고 한다. Full Rate Blending의 의미는 아마도 매 Cycle Blending 연산을 완료할 수 있다는 의미인 것 같다.
Index-driven Vertex Shading (IDVS) Geometry Pipeline
 그림 7: 기존 Clipping/Culling 연산 순서
그림 7: 기존 Clipping/Culling 연산 순서
Bifrost에서 처음 제안된 기술이다. 기존의 Mali GPU의 경우 모든 Vertex Shading 연산이 완료 후 Culling을 통해서 필요 없는 Primitive들을 제거하였다. 이러한 방법은 Bandwidth와 Computation Resource을 낭비하게 된다. 그림 7는 기존 연산 방법이다.
 그림 8: Bifrost GPU Clipping/Culling 연산 순서
그림 8: Bifrost GPU Clipping/Culling 연산 순서
그림 8는 IDVS Pipeline 연산 방법이다. IDVS는 Vertex Shading 연산을 두 단계로 나누어서 실행한다. 먼저 Vertex Position 연산을 완료 후 Culling 연산을 통해 필요 없는 Primitive를 제거한다. 이후 Varying 연산을 수행한다. 글을 읽고 추측한 바에 따르면 아마도 Varying 연산의 Overhead가 큰 것 같다. 그래서 결과적으로 Varying 연산 이전에 Vertex Position 연산을 모두 완료 후 Clipping/Culling 연산을 수행하는 것 같다.
IDVS Pipeline을 사용하면 아래와 같이 크게 2가지 성능 Optimization이 가능하다.
- Position shading is only submitted for small batches of vertices where at least one vertex in each batch is referenced by the index buffer. This allows vertex shading to jump spatial gaps in the index buffer which are never referenced.
- Varying shading is only submitted for primitives with survive the clip-and-cull phase; this removes a significant amount of redundant computation and bandwidth for vertices contributing only to triangles which are culled.
IDVS Pipeline 성능을 최대화하기 위해서 Vertex Position 값과 Non-position Varing 값을 따른 Buffer에 저장하는 것을 추천한다. 이렇게 하면 Culling/Clipping을 통해서 제거된 Varying 값(정확히 표현하면 Varing연산에 필요한 Input을 의미함)들은 Cache에 로딩되는 것을 방지할 수 있다. Cache의 경우 Spatial Locality로 인해서 Varying와 Vertex Position값이 연속적으로 있으면 Vertex Position 값을 로딩하는 시점에 Varying 값도 같이 로딩되는 경우가 발생한다. 이러한 부분을 방지할 필요가 있다고 언급하는 것 같다.
출처
- https://en.wikipedia.org/wiki/Mali_(GPU)
- https://developer.arm.com/graphics/developer-guides/the-bifrost-shader-core