개인적으로 GPU 공부를 하면서 GPGPU의 개념만 이해했다. 실제로 GPU에서 Graphics (Graphics Pipeline) 연산을 어떻게 수행하는지 거의 알지 못한다. 운이 좋게 GPGPU 공부를 하고 실제로 GPU를 많이 사용하는 곳에서 일하게 되면서 GPU 공부를 계속할 수 있게 되었다. 공부하면서 NVIDIA에서 제공하는 “Life of a Triangle”이라는 기사를 읽고 너무 좋은 자료인 것 같아서 정리를 해보았다. 중간중간 모르는 부분도 있고, 내 생각에는 이렇게 동작하지 않을까 하는 부분은 개인 의견(?)도 추가하였다. 틀린 부분을 찾게 되면 수정할 계획이다. 용어나 그림은 NVIDIA GPU를 기반으로 작성하였다.
GPUs are super parallel work distributors
보통 각 Drawcall 마다 그려야 하는 Triangle의 개수는 다르다. 특히 Clipping과 같이 화면에 보이지 않는 부분을 제거하거나, Depth Testing 등을 통해서 실제로 그릴 필요 없는 Fragment을 제거하면 화면에 그려지는 픽셀의 개수는 몇 개 남지 않을 수도 있다. 반대로 모든 삼각형이 화면에 다 표시되어야 하는 경우도 있다. 그래서 이미지를 그리는 Drawcall 연산은 Physical Pipeline 순서를 따르지 않고, Logical Pipeline 순서에 따라 GPU에서 연산을 수행한다. NVIDIA G80 Unified Architecture 이전의 GPU는 각 Pipeline Stage가 GPU에 존재하였고, 하나의 Stage 연산이 완료되면 다음 Stage로 넘어가는 방식으로 Drawcall 연산을 수행하였다. 이러한 방식을 Fixed Function Pipeline이라고 한다. 반면, G80 Unified Architecture의 경우 GPU의 특정 Unit을 재사용하는 방법을 사용한다. 여기서 재사용이라고 하는 부분은 Vertex Shader, Fragment Shader 연산 등을 동일한 Shader Core에서 처리하는 것을 의미이다. 이렇게 여러 Logical Stage를 하나의 Shader Core에서 처리할 수 있으면 Drawcall의 Load에 따라 일을 분배하여 연산을 수행할 수 있다. 하지만, Rasterization 등과 같은 몇몇 부분은 아직도 순차적인 연산이 필요하다.
Physical Pipeline과 Logical Pipeline의 차이
최근에 사용되는 GPU는 Logical Pipeline 순서대로 연산을 수행한다고 한다. 이해한 바에 따르면 특정 Stage (Vertex, Fragment, 등)은 같은 Shader 연산 유닛을 사용하기 때문에 여러 개의 Drawcall이 동시에 실행 가능하다는 의미이다. 하지만, GPU의 특정 연산 유닛 (예를 들어 Rasterization, Color Blending 등)은 Fixed Function에서 순차적으로 실행된다. 과거(G80 Unified Architecture이전) GPU의 경우 Physical Pipeline 순서대로 연산이 수행한다. 이해한 바에 따르면 Fixed Function Unit은 순차적으로 고정된 연산을 수행하는 형태이다.
간단한 예로 두 개의 삼각형 A, B를 그리기 위한 2개의 다른 Drawcall이 GPU에서 동시에 연산을 수행한다고 가정하자. A 삼각형과 B 삼각형이 서로 다른 Logical Stage의 연산을 수행하고 있을 수 있다. 예를 들어 A 삼각형의 특정 부분은 Rasterization Stage 연산을 수행하고 있고, 다른 특정 부분은 Fragment (Pixel) Shader연산을 수행하고 있거나, 벌써 모든 연산이 끝난 부분은 Framebuffer에 저장되어 있다. 이와 더불어 동시에 B 삼각형을 그리기 위해서 B 삼각형 연산에 필요한 Vertex 데이터를 Streaming Multiprocessor (SM)에 Loading하고 있을 수 있다. A, B 삼각형을 그리기 위해서 Logical Pipeline 순서대로 연산을 수행해야 하지만, 각 부분은 서로 다른 Logical Pipeline Stage에서 연산을 수행하고 있을 수 있다. 결과적으로 각 Drawcall은 아주 작은 단위로 나누어져서 GPU에서 연산이 수행되고 있다는 의미이다. 이 부분은 ARM GPU 설명에도 나와 있다. 각 Drawcall은 아주 작은 단위로 나뉘어서 연산을 수행한다. ARM에서 제작한 Mali GPU의 경우 16 x 16 Pixel 단위 (Tile) 단위로 나누어서 연산을 수행한다고 한다 (출처 2). 작게 나누어진 Job은 GPU의 Resource에 따라 동시에 실행 가능하다.
GPU Architecture
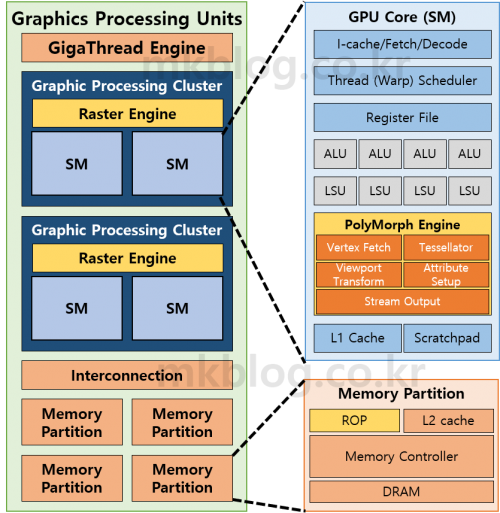 그림 1: GPU Architecture 구조
그림 1: GPU Architecture 구조
이전에 GPU Architecture 관련하여 작성하였다 (출처 3). 해당 자료는 GPGPU 연산에 필요한 부분만 설명하였다. 그림 1은 출처 3에서 나온 그림을 조금 수정하여 Graphic 연산에 필요한 부분을 추가하였다. 이전 그림과 크게 달라진 부분은 PolyMorph Engine에 추가된 5개 정도의 Fixed Function Unit이다.
간단히 GPU 구조에 관해서 설명이 필요하다. GigaThread Engine은 Job (Work)를 분배하고 관리하는 부분이다. GPU는 보통 여러 개의 Graphics Processing Cluster (GPC)로 구성되어 있으며, 각 GPC는 여러 개의 SM과 하나의 Raster Engine으로 구성되어 있다. 이와 더불어 GPU는 아주 큰 Crossbar Interconnection을 가지고 있으며, Job들은 Interconnection을 통하여 각기 다른 GPC/SM으로 이동(Migration)할 수 있다. 마지막으로 Main Memory가 있으며 보통 여러 개의 파티션으로 나누어져 있고, ROP라는 Fixed Function Unit이 Graphics 연산 결과값을 Framebuffer에 저장한다. 다른 추가적인 부분은 출처 3을 참조하기 바란다.
Logical Pipeline Execution
GPU가 Logical Pipeline 연산을 처리하는 순서에 대해서 정리해보았다. 본 설명에서는 Drawcall을 처리하기 위한 데이터가 GPU의 DRAM에 모두 Loading 되어 있다고 가정하였다. 아마 가정이 없으면 단순히 Main Memory에서 GPU Memory로 데이터를 복사하는 과정만 추가하면 되는 것 같다. 그림 2는 Drawcall이 Logical Pipeline 순서에 따라 실행되는 순서를 정리한 그림이다.
 그림 2: Graphics 연산이 실행되는 순서 (출처 1)
그림 2: Graphics 연산이 실행되는 순서 (출처 1)
 그림 3. Rasterization 연산의 위한 Bounding Box 그림 (출처 1)
그림 3. Rasterization 연산의 위한 Bounding Box 그림 (출처 1)
- (Drawcall) 프로그래머가 프로그램을 작성하여 Drawcall를 호출한다. 해당 API Call은 언젠가는 Driver 단에 도달하게 된다. Driver은 간단한(?) Validation 검사를 수행하고 GPU가 이해할 수 있는 Command (GPU-readable Encoding)로 변경하여 Pushbuffer에 저장한다. 많은 Overhead가 발생할 수 있기 때문에 프로그래머는 API를 잘 이해하고 사용해야 한다. OpenGL의 경우 보통 Driver가 해당 API Call을 제대로 사용하고 있는지, 아니면 프로그래머가 실수를 하지 않았는지 모두 Driver 단에서 Validation 검사를 한다. 반면, 최신(?)에 발표된 Vulkan API의 경우 프로그래머가 직접 Validation을 진행해야 한다. 정리하면 효율적으로 Vulkan을 사용하면OpenGL을 사용하는 경우보다 CPU 부하가 적을 수 있다는 의미이다.
- (GPU Command) Pushbuffer에 충분한 Command가 저장될때 까지 기다린다. 특정 시간이 지나거나, 프로그래머가 “flush” Call을 호출하면 Pushbuffer에 있던 Command를 GPU로 보낸다. GPU로 Command를 보내는 작업은 OS의 Support가 필요하다. GPU Host Interface는 Command를 선택하고, Front End는 해당 Command를 처리한다.
- (Primitive Scheduling) 다음 단계에서 GPU의 Primitive Distributor가 Work Distribution을 시작한다. Index Buffer의 Index를 이용해서 삼각형 단위로 Work Batch를 만들고 해당 Work를 GPC로 Scheduling한다.
- 이부분이 개인적으로 궁금했던 부분이다. 보통 OpenGL을 사용하는 경우 Vertex Buffer만을 사용하거나, Vertex Buffer + Index Buffer을 사용하여 Drawcall 연산을 수행할 수 있다. Vertex Buffer만을 사용하는 경우 단순히 메모리에 저장된 Vertex 값을 순서대로 Loading하면 되기 때문에 간단하다. 반면, Index Buffer을 사용하는 경우 Vertex Buffer에 저장되어 있는 데이터를 비순차적으로 Loading해야 한다. 그럼 연산에 필요한 Vertex 값을 Loading을 하기 위해서 Vertex Shader 연산을 수행하는 단계에서 Index Buffer의 값을 먼저 Loading하고 Loading된 Index값을 사용하여 Vertex Buffer의 값을 다시 Loading해야 하는 Overhead가 발생한다. 앞의 설명이 맞다면 Drawcall 연산에서 Vertex Buffer 만을 사용하는 경우와 Vertex Buffer + Index Buffer을 사용하는 경우의 성능의 차이가 발생하게 된다. 그런데 여기 설명에 따르면 Vertex Shader 연산을 수행하기 전에 Primitive Distributor가 Index Buffer에 저장된 Vertex 위치 값을 읽어서 Vertex 연산에 필요한 Vertex 값을 삼각형 Batch 단위로 변경하여 Job을 Scheduling한다고 한다. 이 경우 Vertex Shader 연산을 시작하기 전에 Vertex 값이 정렬된다는 의미이다. 설명된 방법으로 Vertex Shader 연산을 수행하면 Index Buffer + Vertex Buffer을 사용한 경우와 Vertex Buffer만을 사용한 메모리 접근 횟수의 차이가 발생하지 않게 되고 연산 Overhead가 동일하게 된다. 하지만 아마도 Primitive Distributor에서 삼각형 Batch를 생성하는 시간의 차이가 조금 발생하지 않을까 하는 추측을 해본다. 추가로 궁금했던 부분은 Primitive Distributor가 어디에 위치하는지에 대한 질문이다. 아마도 해당 부분은 GigaThread Engine에 포함되어 있지 않을까 하는 추측을 할 수 있다.
- (Vertex Fetch) GPC/SM에 Work가 할당되면 PolyMorph Engine의 Vertex Fetch 로직이 Triangle Index를 사용하여 Vertex Data 값을 로딩한다. 아마도 3단계에서 생성한 Triangle Work Batch를 의미하는 것 같다.
- (Vertex Shader) Vertex Data Fetching이 완료되면 Warp 단위로 Vertex Shader 연산을 수행한다. 해당 연산은 GPGPU Application에서 Thread를 실행하는 순서와 같다. GPGPU Application의 동작 원리는 GPGPU Series에 따로 작성하였다.
- (Tessellation/Geometry Shader, 추측) 이 단계는 추측이다. 혹시 관련된 자료를 찾게 되면 수정할 계획이다. 특정 삼각형의 Vertex/Tessellation/Geometry Shader 연산은 같은 SM 내에서 실행하는 것 같다. 출처 1 그림에 따르면 Vertex Shader (VS), Geometry Shader (GS), Viweport Transform이 완료되면 Work Distribution을 다시 한다. 아마도 Viewport Transform 이전 단계의 연산은 같은 SM에서 실행할 것 같다는 추측을 하게 된다. 출처 4에 따르면 Tessellation Shader은 Vertex Shader와 Geometry Shader 사이에 존재하는 단계이다.
- (Viewport Transform) Vertex/Tessellation/Geometry Shader 연산이 완료되면 Viewport Transform 연산을 수행한다. Viewport Transform 연산은 앞 단계에서 연산한 삼각형 좌표들을 화면에 표시하기 위한 2D Screen 좌표로 변경하는 단계이다. Vertex Shader 등에서 사용하는 좌표는 보통 X, Y, Z로 구성된 3D 좌표이다. 하지만, 우리가 보는 화면은 2D만을 표시할 수 있기 때문에 변환이 필요하다. 결과적으로 3D 좌표를 모니터 Screen에 표시하기 위한 2D 좌표로 변경하는 연산이 Viewport Transform 이다 (출처 5). Viewport Transform 연산이 완료되면 모든 좌표는 -1.0 에서 1.0 사이 값으로 변경된다. 추가로 Depth 값도 생성되는 것 같다.
- (Rasterization) 그림 3과 같이 Screen 좌표로 변경된 삼각형을 여러 개의 Bounding Box로 나누어서 GPC 내부의 Raster Engine으로 보낸다. 각 Engine은 하나 또는 여러 개의 Bounding Box 박스에 대해서 Rasterization 연산을 수행할 수 있다. 해당 Work는 Work Distributor Crossbar를 통해서 보내진다 (?). Raster Engine은 Rasterization 연산을 수행한다. Rasterization은 Viewport Transform에서 나온 좌표를 기준으로 Fragment (Pixel) 단위로 변경하는 작업을 수행한다. Viewport Transform 연산이 완료되면 각 좌표는 -1.0에서 1.0 사이 좌표지만 우리가 보는 모니터는 Pixel로 구성되어 있다. 예를 들어 1080 x 720개의 Pixel로 구성된 화면에 (0.33, 0.33)의 좌표는 어느 Pixel에 해당하는 위치를 찾아야 한다. Rasterization 연산은 (0.33, 0.33)등의 좌표를 1080 x 720개의 Pixel의 어느 위치에 존재하게 되는지를 찾는 단계이다. Rasterization 연산이 완료되면 Viewport Transform에서 생성된 좌표 대신 삼각형의 Pixel 위치를 알게 된다.
- (Attribute Setup) 여기서 약간의 의문이 생긴다. 출처 1 그림에서는 Rasterization 연산을 먼저 수행한다. 하지만, 글에서는 Attribute Setup 설명을 먼저 한다. 그림의 순서가 맞다고 가정을 하고 설명을 작성하였다. Attribute Setup은 Interpolation 연산을 수행하여 Fragment (Pixel) Shader 연산에 필요한 Input을 생성하는 단계이다. Interpolation 연산은 Vertex Shader 연산 Output을 Fragment Shader의 Input으로 넘기는 과정에서 삼각형의 3개의 Output 값을 평균화하여 특정 Fragment 위치에 Input의 값을 생성하는 과정이다. 간단한 예로 삼각형 3점에서 서로 다른 색상 값을 Fragment Shader로 넘겨주면 무지개 색상의 삼각형을 그리게 된다. 여기서 무지개색을 만드는 과정을 Interpolation이라고 한다.
- (Fragment (Pixel) Shader) 다음으로 Fragment Shader 연산을 수행한다. Fragment Shader 연산 기본 단위는 2 x 2 (Quad) 이다. NVIDIA의 경우 8개의 Quad를 한 개의 Warp 단위로 변경하여 연산을 수행한다고 한다. 출처 2에서 ARM GPU 설명에서도 Quad라는 단어가 나온다. 예상하기로 Anti-Aliasing 등과 같이 Edge를 부드럽게 하는 연산 등에 효율적이라는 정도만 알고 있다. 추가로 출처 1에 따르면 Warp 단위로 실행하면 Pixel Quad의 결과 값들을 공짜로 읽어 올 수 있다고 한다 (NV_shader_thread_group). 하지만 2 x 2 (Quad) 단위로 Fragment 연산을 수행하는 정확한 이유를 잘 모르겠다. Quad에 대한 부분은 추가로 공부할 필요가 있는 부분이다. Fragment 연산을 수행하는 방법은 Vertex Shader 연산/GPGPU 연산을 수행하는 방법과 동일하다고 판단된다.
- (ROP/Framebuffer) 드디어 마지막 단계이다. 여기까지 연산을 수행하면 Drawcall 순서를 보장해줘야 한다. GPU에서 여러 개의 Drawcall이 동시에 수행되고 있기 때문에 연산의 Overhead가 적은 Drawcall이 먼저 실행된 Drawcall 보다 먼저 연산이 완료되는 경우가 발생할 수 있다. 결과적으로 마지막 단계에서는 Original API Call순서를 맞춰서 ROP (Render Output Unit)에 전달된다. 역시 어떤 연산장치가 Original API Call 순서를 보장하는지에 대한 설명이 없다. GPU는 보통 여러 개의 ROP를 가지고 있으면 Vertex/Fragment Shader에 Job이 분배되는 방식과 동일하게 Interconnection (Crossbar)을 통해서 Job이 전달된다. ROP는 Depth-Testing, Blending 등의 연산을 수행한다. Color/Depth등의 연산은 Atomic (순차적인) 연산을 보장한다. Atomic 연산을 보장하지 않으면 Color, Depth 값에 서로 다른 Drawcall (삼각형)의 결과값을 가지게 될 수도 있기 때문이다. 모든 Drawcall이 완료되면 Frambuffer (최종 결과)의 값(이미지)은 모니터에 출력된다.
여기까지가 Logical Pipeline이 실제 GPU에서 어떻게 실행되는지의 간단한 설명이다. 앞에서 설명한 것과 같이 GPU는 동시에 여러 개의 Drawcall 연산을 처리하고 있기 때문에 CPU에서 Synchronization등을 수행하면 GPU Utilization이 크게 하락하게 된다.
출처
- https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
- https://developer.arm.com/graphics/developer-guides/tile-based-rendering
- https://mkblog.co.kr/2018/10/01/gpgpu-series-3-gpu-architecture-overview/
- https://www.3dgep.com/introduction-to-opengl-and-glsl/
- https://learnopengl.com/Getting-started/Coordinate-Systems