GPU의 메모리 구조에 대해서 정리를 해보았다. 최근 GPU는 CPU와 비슷한 메모리 계층 구조를 가지고 있다. GPGPU를 지원하는 초창기 GPU는 CPU와는 다소 다른 메모리 계층 구조를 가졌던 것으로 알려져 있다. 하지만 GPU를 General Purpose 연산 목적으로 많이 사용하면서 점차 CPU와 비슷한 메모리 계층 구조로 바뀌게 된 것 같다.
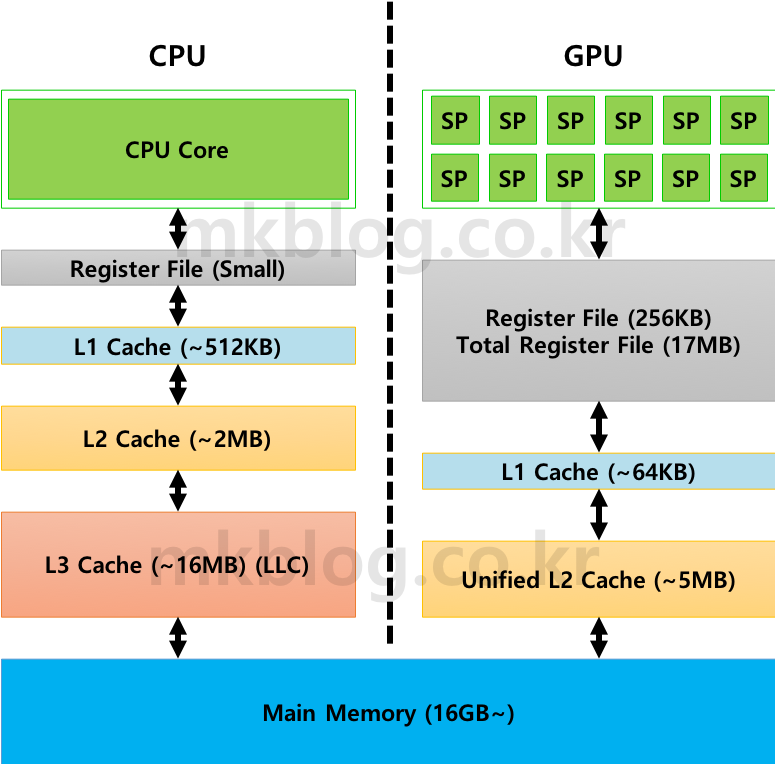 그림 1: CPU, GPU Memory 구조 (출처 1, 2)
그림 1: CPU, GPU Memory 구조 (출처 1, 2)
그림 1은 CPU Memory 계층 구조와 GPU Memory 계층 구조를 보여준다. CPU의 경우 보통 Register, L1, L2, L3 (Last-Level Cache)로 구성되어 있다. 요즘 시장에 출시되는 CPU의 경우 1개 이상의 코어를 가지고 있으므로 Private Cache, Shared Cache로 구성되어 있다. Private Cache는 하나의 코어에 할당되어서 전용 메모리 공간으로 사용되는 공간이다. 반면 보통 Last-Level Cache (LLC)는 Shared Memory 영역으로 모든 코어가 저장 공간을 공유하는 구조를 가지고 있다. GPU의 경우 CPU와 비슷하게 Register, L1, L2로 구성되어 있다. L1 Cache의 경우 Private Cache로 각 SM이 1개씩 가지고 있다. L2 Cache의 경우 모든 SM이 Shared 하는 형태로 구성되어 있다.
CPU와 GPU는 비슷한 메모리 계층 구조를 가지지만 각 메모리 공간의 크기는 상당히 차이가 크다. 보통 CPU의 경우 각 Core당 수백개의 Register만 가진다. L1, L2, L3 Cache 사이즈는 보통 Register의 사이즈보다 크다. 그래서 CPU는 Cache 사이즈에 따른 성능 향상이 크다. 더 비싼 CPU를 구매할수록 CPU Core Clock 및 Cache 사이즈가 증가한다. 반면 GPU의 경우 Register의 크기가 상당히 크다. 보통 한 개의 SM에 대략 6.5만개 정도의 Register를 가진다. 32-Bit Register로 가정을 하면 Register 사이즈는 대략 256 KB (4 Byte X 65,000개)이다. 보통 1개의 GPU는 10개 이상의 SM으로 구성되어 있으니 전체 크기가 대략 2MB를 넘게 된다 (최근 발표된 Turing Architecture의 경우 GPU 총 Register 사이즈가 17MB정도이다 (출처2)). GPU의 각 SM은 동시에 실행되는 수백개의 Thread의 Context 정보를 저장하기 위해 큰 Register를 가진다. Register의 사이즈에 반해 L1 Cache 사이즈는 상당히 작다. 그래서 GPU의 경우 L1 Cache 사이즈에 따른 성능 향상 폭이 크지 않는 것으로 알려져 있다. GPU의 SM은 기본적으로 수백개의 Thread 연산을 동시에 수행하는데 Private Cache의 크기가 수십 KB에 불과하다. 각 Thread가 실제로 사용할 수 있는 L1 Cache 공간은 수십 Byte 정도밖에 되지 않는다. 그래서 GPGPU-Sim 등을 사용해서 GPGPU Application 연산을 수행하면 L1 Cache Miss Rate가 90%를 넘는 경우가 많다.
GPU는 CPU와 달리 추가로 Shared Memory (Programmable Memory), Constant Cache, Texture Cache 을 가지고 있다. Shared Memory의 경우 L1 Cache와 비슷한 구조로 알려져 있다. 실제 NVIDIA GPU의 경우 Shared Memory와 L1 Cache를 공유하는 구조로 사이즈를 변경할 수 있다. 예를 들어 64KB 사이즈 메모리 공간을 16KB L1 Cache와 48KB Shared Memory로 나누어 사용할 수 있다. 반대로도 변경할 수 있다. Shared Memory는 Programmable Memory로 GPGPU 프로그래밍 하는 단계에서 개발자의 선택에 따라 실제 사용 여부가 달라진다. NVIDIA에서 제공하는 Matrix Multiplication 연산 예제 등에서 Shared Memory를 사용하여 성능 향상을 하는 방법을 설명하기도 한다. Shared Memory를 효율적으로 사용하면 GPGPU Application 성능을 대폭 개선할 수도 있다. Constant Cache와 Texture Cache의 경우 개별적인 공간을 가지고 있다. Constant, Texture Cache의 경우 GPGPU 연산에서 거의 사용하지 않는다.
출처
- https://en.wikichip.org/wiki/intel/core_i9/i9-9900k
- https://www.intel.com/content/www/us/en/products/processors/core/i9-processors/i9-9900k.html
- https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
유익한 정보 감사합니다.
글 읽고 Comment 남겨 주셔서 감사합니다!
글 잘 읽었습니다. 감사합니다.
안녕하세요. 글 읽어주셔서 감사합니다.
블로그 포스트 덕분에 GPGPU 구조에 대해 많이 알 수 있었습니다.
좋은 글들 감사합니다ㅎㅎ
글 남겨주셔서 감사합니다.
도움이 되었으면 좋겠습니다!
글 정말 감사합니다. gpu 관련 정보가 너무 없네요…
도움이 되셨으면 좋겠네요:)
좋은 글 감사합니다.