조금 고민을 하다가 GPGPU (CUDA) Application의 Thread Hierarchy에 대해서 작성하기 이전에 GPU Architecture에 대해 간단하게 설명을 먼저 작성하려 한다. 아주 간략한 용어들만 설명하는 단계이다. 부족한 부분은 뒤에 추가로 상세히 설명을 진행할 예정이다. 글에서 사용하는 GPU Architecture 용어는 NVIDIA White Paper에서 사용하는 것이다.
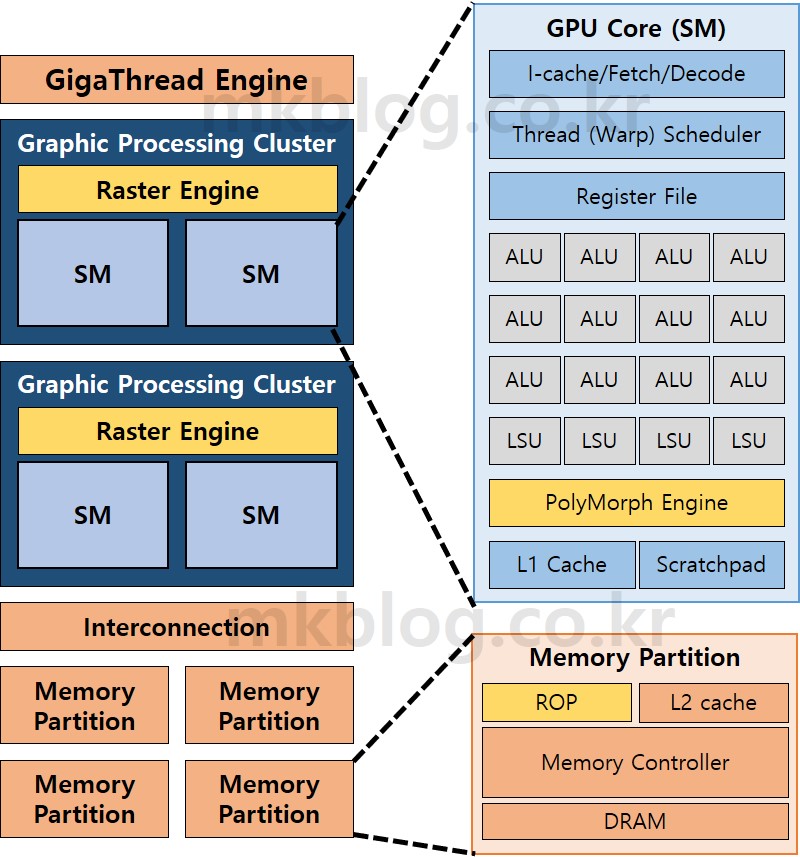 그림 1: GPU Architecture
그림 1: GPU Architecture
앞글에서 짧게 설명했듯이 요즘 구매하는 GPU는 Fixed Function Unit과 Programmable Stage를 실행하는 GPU Core로 구성되어 있다. 그림 1은 NVIDIA GPU Block Diagram이다. 통일성을 유지하기 위해 Fixed Function Unit은 노랑색 바탕으로 그림을 그렸고, Programmable Stage 연산을 수행하는 부분은 파란색 바탕으로 그림을 그렸다. Fixed Function Unit과 Programmable Stage가 모두 사용하거나 큰 연관성이 없는 부분은 자주색(?) 바탕으로 표시하였다. 그림 1은 NVIDIA GPU의 대략적인 그림이다. 각 세대 (Tesla, Fermi, Kepler, Maxwell, Volta, RTX, etc)마다 조금씩 차이가 있다. 하지만 전체적인 GPU 실행 순서를 이해하는 데는 큰 차이가 없다.
NVIDIA GPU는 크게 Thread Block Scheduler (GigaThread Engine), Streaming Multiprocessor (SM), Interconnection Network, Memory, Fixed Function Hardware로 구성되어 있다. 순서(?)대로 설명을 시작하면 GPU는 한 개의 Thread Block Scheduler를 가진다. Thread Block Scheduler는 Thread Block (TB or Cooperative Thread Array (CTA))라는 단위의 Thread Group을 SM에 Scheduling 하는 역할을 수행한다. 논문에 따르면 Thread Block Scheduler는 Round-Robin Scheduling 순서를 따른다고 한다. 쉽게 설명하면 여러 개의 TB가 있으며, 순서대로 SM0, SM1, SM2로 Scheduling한다 (출처 1, 2).
다음은 Graphics Processing Cluster (GPC)라는 부분이다. 기본적으로 GPU는 한 개의 Raster Engine과 여러 개의 SM으로 구성되어 있다. Raster Engine은 Fixed Function Unit으로 Triangle (Vertex 3개를 연결한 Primitive)를 Fragment 연산을 수행하기 위해서 Pixel로 변경하는 부분이다. Raster Engine은 GPGPU 연산을 수행할 때 사용되지 않기 때문에 추가적인 설명은 하지 않겠다 (솔직히 잘 모르기도하다). 개인적인 생각인데 GPC라는 개념은 Graphics 연산을 위해 존재하는 것 같다. GPC에 포함된 SM이 GPGPU 연산의 핵심이다. SM은 Streaming Processor (SP or ALUs), Load/Store Unit (LSU), L1 Cache, Programmable Cache (Scratchpad Memory), PolyMorph Engine, Texture Cache등으로 구성되어 있다. GPGPU Application의 연산이 수행되는 부분이 SM이라고 생각하면 된다. SM의 동작 순서와 상세한 설명은 GPGPU Application Thread Hierarchy 설명 이후 작성할 예정이다. 추가로 PolyMorph Engine은 Fixed Function Unit이다. Vertex Fetch, Tessellation, Viewport Transform 등의 고정된 연산을 수행하는 장치이다.
다음은 Interconnection Network와 Memory 부분이다. 우선 Memory는 여러 개의 Memory Partition으로 나누어져 있다. Interconnection은 Memory Partition과 SM을 연결하는 부분이다. 보통 SM 간의 데이터 통신은 거의(?) 발생하지 않는다. CPU의 경우 Cache Coherency 등의 문제로 인해서 CPU Core의 Private Cache에 저장된 데이터가 다른 CPU Core로 바로 전송되는 경우도 있다. 하지만, GPU의 경우 SM의 Cache Coherency 문제를 해결하기 위해 Write-Through Cache를 사용한다. 결과적으로 Interconnection은 SM에 실행 중이 Thread의 Data Load/Store 명령어가 필요한 Data를 Fetching(Loading) 하거나 Storing 하기 위해서 사용된다. Memory는 보통 Host Memory (CPU Side Memory)의 데이터를 복사하여 저장하거나, GPGPU Application의 중간값들을 저장하는 공간이다.
우선 정말 간단하게 GPU 구조에 관해서 설명해보았다. 간단히 GPU 내부에 사용되는 용어를 알아보기 위해서 글을 작성하였다. 뒤에 이어질 글은 GPGPU Application의 Thread Hierarchy 대해서 자세히 설명할 예정이다.
출처
- Analyzing CUDA workloads using a detailed GPU simulator
- Improving GPGPU resource utilization through alternative thread block scheduling
” CPU의 경우 Cache Coherency 등의 문제로 인해서 CPU Core의 Private Cache에 저장된 데이터가 다른 CPU Core로 바로 전송되는 경우도 있다. ” 이 부분이 잘 이해가 되지 않네요. Cache Coherency를 통해 캐시의 데이터를 공유 메모리(L2, L3)로 옮기는 것이 아니라 CPU Core의 L1 캐시간에 데이터 전송이 이루어질 수 있나요??
안녕하세요. 피드백 주셔서 감사합니다.
제가 작성 당시 생각했던 부분은 아래와 같습니다. 해당 부분은 한 차례 더 확인해보도록 하겠습니다.
CPU Exclusive Cache의 경우 Cache Coherence를 확인하는 과정에서 A 코어의 Private Cache에서 B 코의 Private Cache로 데이터를 전송하면서 Cache의 State Field를 변경하는 경우가 있습니다. 예를 들어 A 코어의 Private Cache에 Modified 된 Cache Line이 있고, B 코어에서 해당 메모리 Address 접근을 시도하면 A 코어의 Cache Line의 State Field를 Shared로 변경하면서 Cache Line의 데이터를 B로 보낸다는 의미였습니다.
보통 GPU의 경우 Write Through를 사용하기 때문에 Shared L2 Cache에 값이 저장되어 있습니다. 그래서 CPU와 달리 Cache Coherence를 확인하는 과정이 필요 없으며, SM의 Private L1 Cache에서 다른 L1 Cache로 값을 보낼 필요가 없다는 의미였습니다.