목차: Series 1 – Index + Methodology (Link)
이전 글: Series 7 – Iteration vs. Recursion (Link)
다음 글: Series 9 – Dielectrics + Snell’s Law (Link)
출처 1에서 출처 2의 Chapter 8 내용부터는 추가적인 설명 없이 코드만 공유하고 있다. Chapter 8부터는 앞에 설명한 내용을 기반으로 CUDA 코드를 작성하면 된다고 한다. 그래서 Series 8부터는 변경된 코드 부분과 성능에 대해서만 간단히 작성할 계획이다.
Chapter 8 “Metal”에 관련된 코드를 작성하기 위해서 Material이라는 새로운 Class를 추가해야 한다. Class의 함수를 GPU가 호출 할 수 있도록 “__device__”를 함수 앞에 추가하면 된다. 아래 코드 1은 Material Class 관련 코드이다.
코드 1: Material Class 코드
#ifndef MKMATERIAL_H
#define MKMATERIAL_H
#include "mkVec3.h"
#include "mkRay.h"
struct hitRecord;
//MK: (코드 1) Material Class를 새로 추가함
class material{
public:
__device__ virtual bool scatter(const ray &rIn, const hitRecord &rec, vec3 &attenuation, ray &scattered, curandState *localRandState) const = 0;
};
class lambertian : public material{
public:
__device__ lambertian(const vec3 &a): albedo(a) {}
__device__ virtual bool scatter(const ray &rIn, const hitRecord &rec, vec3 &attenuation, ray &scattered, curandState *localRandState) const {
vec3 target = rec.p + rec.normal + randomInUnitSphere(localRandState);
scattered = ray(rec.p, unitVector(target-rec.p));
attenuation = albedo;
return true;
}
private:
vec3 albedo;
};
class metal : public material{
public:
__device__ metal(const vec3 &a, float f): albedo(a){
if( f < 1.0f ){
fuzz = f;
}
else{
fuzz = 1;
}
}
__device__ virtual bool scatter(const ray &rIn, const hitRecord &rec, vec3 &attenuation, ray &scattered, curandState *localRandState) const{
vec3 reflected = reflect(unitVector(rIn.direction()), rec.normal);
scattered = ray(rec.p, unitVector(reflected + fuzz * randomInUnitSphere(localRandState)));
attenuation = albedo;
return (dot(scattered.direction(), rec.normal) > 0);
}
private:
vec3 albedo;
float fuzz;
};
#endifMaterial Class에서 사용하는 함수를 Vector 파일에 추가로 작성하였다. 코드 2는 Material Class가 사용하는 함수를 추가한 Vector 코드이다. 추가로 코드 3은 Sphere Class가 Material Class를 사용할 수 있도록 변경한 Sphere 코드이다.
코드 2: Vec3 파일 코드
#ifndef MKVEC3_H
#define MKVEC3_H
#include <math.h>
#include <stdlib.h>
#include <iostream>
#include <curand_kernel.h>
//MK: __host__, __device__를 추가해서 CPU/GPU 모두 호출가능하도록 수정함
class vec3{
public:
__host__ __device__ vec3(){}
__host__ __device__ vec3(float e0, float e1, float e2){
element[0] = e0;
element[1] = e1;
element[2] = e2;
}
__host__ __device__ inline float x() const{ return element[0];}
__host__ __device__ inline float y() const{ return element[1];}
__host__ __device__ inline float z() const{ return element[2];}
__host__ __device__ inline float r() const{ return element[0];}
__host__ __device__ inline float g() const{ return element[1];}
__host__ __device__ inline float b() const{ return element[2];}
__host__ __device__ inline const vec3& operator+() const{ return *this;}
__host__ __device__ inline vec3 operator-() const {return vec3(-element[0], -element[1], -element[2]);}
__host__ __device__ inline float operator[] (int i) const {return element[i];}
__host__ __device__ inline float &operator[] (int i) {return element[i];}
__host__ __device__ inline vec3& operator+=(const vec3 &v){
element[0] += v.element[0];
element[1] += v.element[1];
element[2] += v.element[2];
return *this;
}
__host__ __device__ inline vec3& operator-=(const vec3 &v){
element[0] -= v.element[0];
element[1] -= v.element[1];
element[2] -= v.element[2];
return *this;
}
__host__ __device__ inline vec3& operator*=(const vec3 &v){
element[0] *= v.element[0];
element[1] *= v.element[1];
element[2] *= v.element[2];
return *this;
}
__host__ __device__ inline vec3& operator/=(const vec3 &v){
element[0] /= v.element[0];
element[1] /= v.element[1];
element[2] /= v.element[2];
return *this;
}
__host__ __device__ inline vec3& operator*=(const float t){
element[0] *= t;
element[1] *= t;
element[2] *= t;
return *this;
}
__host__ __device__ inline vec3& operator/=(const float t){
float k = 1.0/t;
element[0] *= k;
element[1] *= k;
element[2] *= k;
return *this;
}
__host__ __device__ inline float length() const{
return sqrt(element[0] * element[0] + element[1] * element[1] + element[2] * element[2]);
}
__host__ __device__ inline float squared_length() const{
return (element[0] * element[0] + element[1] * element[1] + element[2] * element[2]);
}
__host__ __device__ inline void make_unit_vector(){
float k = 1.0 / (sqrt(element[0] * element[0] + element[1] * element[1] + element[2] * element[2]));
element[0] *= k;
element[1] *= k;
element[2] *= k;
};
float element[3];
};
inline std::istream& operator>>(std::istream &is, vec3 &t){
is >> t.element[0] >> t.element[1] >> t.element[2];
return is;
}
inline std::ostream& operator<<(std::ostream &os, const vec3 &t){
os << t.element[0] << t.element[1] << t.element[2];
return os;
}
__host__ __device__ inline vec3 operator+(const vec3 &v1, const vec3 &v2){
return vec3(v1.element[0] + v2.element[0], v1.element[1] + v2.element[1], v1.element[2] + v2.element[2]);
}
__host__ __device__ inline vec3 operator-(const vec3 &v1, const vec3 &v2){
return vec3(v1.element[0] - v2.element[0], v1.element[1] - v2.element[1], v1.element[2] - v2.element[2]);
}
__host__ __device__ inline vec3 operator*(const vec3 &v1, const vec3 &v2){
return vec3(v1.element[0] * v2.element[0], v1.element[1] * v2.element[1], v1.element[2] * v2.element[2]);
}
__host__ __device__ inline vec3 operator/(const vec3 &v1, const vec3 &v2){
return vec3(v1.element[0] / v2.element[0], v1.element[1] / v2.element[1], v1.element[2] / v2.element[2]);
}
__host__ __device__ inline vec3 operator*(const float t, const vec3 &v){
return vec3(t * v.element[0], t * v.element[1], t * v.element[2]);
}
__host__ __device__ inline vec3 operator/(const vec3 &v, const float t){
return vec3(v.element[0]/t, v.element[1]/t, v.element[2]/t);
}
__host__ __device__ inline vec3 operator*(const vec3 &v, const float t){
return vec3(v.element[0] * t, v.element[1] * t, v.element[2] * t);
}
__host__ __device__ inline float dot(const vec3 &v1, const vec3 &v2){
return (v1.element[0] * v2.element[0] + v1.element[1] * v2.element[1] + v1.element[2] * v2.element[2]);
}
__host__ __device__ inline vec3 cross(const vec3 &v1, const vec3 &v2){
return vec3(
(v1.element[1] * v2.element[2] - v1.element[2] * v2.element[1]),
-(v1.element[0] * v2.element[2] - v1.element[2] * v2.element[0]),
(v1.element[0] * v2.element[1] - v1.element[1] * v2.element[0])
);
}
__host__ __device__ inline vec3 unitVector(vec3 v){
return (v/v.length());
}
//MK: (코드 2) 기존 Main에 있던 함수를 Vec3 파일로 이동함
//MK: __device__를 추가하여서 GPU에서 사용가능 하도록 변경함
#define RANDVEC3 vec3(curand_uniform(localRandState), curand_uniform(localRandState), curand_uniform(localRandState))
__device__ vec3 randomInUnitSphere(curandState *localRandState){
vec3 p;
do{
p = 2.0f * RANDVEC3 - vec3(1.0, 1.0, 1.0);
} while (p.squared_length() >= 1.0f);
return p;
}
__device__ vec3 reflect(const vec3 &v, const vec3 & n){
return v - 2 * dot(v, n) * n;
}
#endif코드 3: Sphere 파일 코드
#ifndef MKSPHERE_H
#define MKSPHERE_H
#include "mkHitable.h"
#include "mkMaterial.h"
class sphere: public hitable{
public:
__device__ sphere(){}
__device__ sphere(vec3 cen, float r, material *ptr) : center(cen), radius(r), matPtr(ptr) {}
__device__ virtual bool hit(const ray &r, float tMin, float tMax, hitRecord &rec) const {
vec3 oc = r.origin() - center;
float a = dot(r.direction(), r.direction());
float b = dot(oc, r.direction());
float c = dot(oc, oc) - radius * radius;
float discriminant = b*b - a*c;
if(discriminant > 0){
float temp = (-b - sqrt(discriminant))/a;
//MK: 구의 가까운 부분 부터 Hit여부를 판단함
if(temp < tMax && temp > tMin){
rec.t = temp;
rec.p = r.pointAtParameter(rec.t);
rec.normal = (rec.p - center) / radius;
//MK: (코드 3) 구의 Material 정보를 저장함
rec.matPtr = matPtr;
return true;
}
temp = (-b + sqrt(discriminant))/a;
if(temp < tMax && temp > tMin){
rec.t = temp;
rec.p = r.pointAtParameter(rec.t);
rec.normal = (rec.p - center) / radius;
//MK: (코드 3) 구의 Material 정보를 저장함
rec.matPtr = matPtr;
return true;
}
}
return false;
}
vec3 center;
float radius;
material *matPtr;
};
#endif마지막 아래 코드 4는 Main 함수 코드이다. 기존 2개의 구에서 4개의 구를 그릴 수 있도록 변경하였다. 이와 더불어 Material Class를 사용할 수 있도록 Sphere 생성 부분을 추가하였다. 새로운 구를 추가하고 Material Class를 사용하기 때문에 제거하는 부분도 수정이 필요하다.
코드 4: Main 파일 코드
#include <fstream>
#include "mkRay.h"
#include <time.h>
#include "mkSphere.h"
#include "mkHitablelist.h"
#include <float.h>
#include <curand_kernel.h>
#include "mkCamera.h"
#include "mkMaterial.h"
#include "mkVec3.h"
using namespace std;
//MK: FB 사이즈
int nx = 1200;
int ny = 600;
int ns = 100;
int numObject = 4;
// limited version of checkCudaErrors from helper_cuda.h in CUDA examples
//MK: #val은 val 전체를 String으로 Return 함 (출처 3)
#define checkCudaErrors(val) check_cuda( (val), #val, __FILE__, __LINE__ )
//MK: Error 위치를 파악하기 위해서 사용
void check_cuda(cudaError_t result, char const *const func, const char *const file, int const line) {
if (result) {
cerr << "MK: CUDA ERROR = " << static_cast<unsigned int>(result) << " at " << file << ":" << line << " '" << func << "' \n";
// Make sure we call CUDA Device Reset before exiting
cudaDeviceReset();
exit(99);
}
}
//MK: (코드 1) 새로운 구와 Material 정보를 추가함
__global__ void mkCreateWorld(hitable **dList, hitable **dWorld, camera **dCamera, int numObject){
if(threadIdx.x == 0 && blockIdx.x == 0){
*(dList) = new sphere(vec3(0, 0, -1), 0.5, new lambertian(vec3(0.8, 0.3, 0.3)));
*(dList + 1) = new sphere(vec3(0, -100.5, -1), 100, new lambertian(vec3(0.8, 0.8, 0.0)));
*(dList + 2) = new sphere(vec3(1, 0, -1), 0.5, new metal(vec3(0.8, 0.6, 0.2), 0.3));
*(dList + 3) = new sphere(vec3(-1, 0, -1), 0.5, new metal(vec3(0.8, 0.8, 0.8), 1.0));
*dWorld = new hitableList(dList, numObject);
*dCamera = new camera();
}
}
__device__ vec3 color(const ray &r, hitable **dWorld, curandState *localRandState){
ray curRay = r;
vec3 curAttenuation = vec3(1.0, 1.0, 1.0);
for(int i = 0; i < 50; i++){
hitRecord rec;
if((*dWorld)->hit(curRay, 0.001f, FLT_MAX, rec)){
ray scattered;
vec3 attenuation;
if(rec.matPtr->scatter(curRay, rec, attenuation, scattered, localRandState)){
curAttenuation *= attenuation;
curRay = scattered;
}
else{
return vec3(0.0, 0.0, 0.0);
}
}
else{
vec3 unitDirection = unitVector(curRay.direction());
float t = 0.5f * (unitDirection.y() + 1.0f);
vec3 c = (1.0f - t) * vec3(1.0, 1.0, 1.0) + t * vec3(0.5, 0.7, 1.0);
return curAttenuation * c;
}
}
return vec3(0.0, 0.0, 0.0);
}
__global__ void mkRender(vec3 *fb, int max_x, int max_y, int num_sample, camera **cam, hitable **dWorld) {
//MK: Pixel 위치 계산을 위해 ThreadId, BlockId를 사용함
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = threadIdx.y + blockIdx.y * blockDim.y;
//MK: 계산된 Pixel 위치가 FB사이즈 보다 크면 연산을 수행하지 않음
if((i >= max_x) || (j >= max_y)){
return;
}
//MK: FB Pixel 값 계산
int pixel_index = j*max_x + i;
curandState rand_state;
//curand_init(1984, pixel_index, 0, &rand_state);
curand_init(pixel_index, 0, 0, &rand_state);
vec3 col(0, 0, 0);
for(int s = 0; s < num_sample; s++){
float u = float(i + curand_uniform(&rand_state))/float(max_x);
float v = float(j + curand_uniform(&rand_state))/float(max_y);
ray r = (*cam)->get_ray(u, v);
col += color(r, dWorld, &rand_state);
}
fb[pixel_index] = col/float(num_sample);
}
//MK: (코드 1) 새로운 구와 Material 정보를 제거하도록 변경함
__global__ void mkFreeWorld(hitable **dList, hitable **dWorld, camera **dCamera, int numObject){
if(threadIdx.x == 0 && blockIdx.x == 0){
for(int i = 0; i < numObject; i++){
delete ((sphere *) dList[i])->matPtr;
delete dList[i];
}
delete *dWorld;
delete *dCamera;
}
}
int main() {
//MK: Thread Block 사이즈
int tx = 8;
int ty = 8;
cout << "MK: Rendering a " << nx << "x" << ny << " Image ";
cout << "MK: in " << tx << "x" << ty << " Thread Blocks.\n";
clock_t start, stop;
start = clock();
int num_pixels = nx*ny;
size_t fb_size = 3*num_pixels*sizeof(float);
//MK: FB 메모리 할당 (cudaMallocManaged 는 Unitifed Memory를 사용 할 수 있도록 함)
//MK: 필요에 따라 CPU/GPU에서 GPU/CPU로 데이터를 복사함
vec3 *fb;
checkCudaErrors(cudaMallocManaged((void **)&fb, fb_size));
hitable **dList;
hitable **dWorld;
camera **dCamera;
//MK: (코드 1) 새로운 구를 추가할 수 있도록 변경함
checkCudaErrors(cudaMalloc((void **) &dList, numObject * sizeof(hitable *)));
checkCudaErrors(cudaMalloc((void **) &dWorld, sizeof(hitable *)));
checkCudaErrors(cudaMalloc((void **) &dCamera, sizeof(camera *)));
mkCreateWorld<<<1, 1>>>(dList, dWorld, dCamera, numObject);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaDeviceSynchronize());
//MK: GPU (CUDA) 연산을 위해서 Thread Block, Grid 사이즈 결정
dim3 blocks(nx/tx+1,ny/ty+1);
dim3 threads(tx,ty);
//MK: CUDA 함수 호출
mkRender<<<blocks, threads>>>(fb, nx, ny, ns, dCamera, dWorld);
checkCudaErrors(cudaGetLastError());
//MK: CUDA 연산이 완료되길 기다림
checkCudaErrors(cudaDeviceSynchronize());
//MK: 연산 시간과 끝 부분을 계산하여서 연산 시간을 측정함
//MK: CPU 코드와 동일하게 결과를 파일에 작성
string fileName = "Ch8_gpu.ppm";
ofstream writeFile(fileName.data());
if(writeFile.is_open()){
writeFile.flush();
writeFile << "P3\n" << nx << " " << ny << "\n255\n";
for (int j = ny-1; j >= 0; j--) {
for (int i = 0; i < nx; i++) {
size_t pixel_index = j*nx + i;
int ir = int(255.99 * fb[pixel_index].r());
int ig = int(255.99 * fb[pixel_index].g());
int ib = int(255.99 * fb[pixel_index].b());
writeFile << ir << " " << ig << " " << ib << "\n";
}
}
writeFile.close();
}
mkFreeWorld<<<1, 1>>>(dList, dWorld, dCamera, numObject);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaFree(dList));
checkCudaErrors(cudaFree(dWorld));
checkCudaErrors(cudaFree(fb));
checkCudaErrors(cudaFree(dCamera));
//MK: 연산 시간과 끝 부분을 계산하여서 연산 시간을 측정함
stop = clock();
double timer_seconds = ((double)(stop - start)) / CLOCKS_PER_SEC;
cout << "MK: GPU (CUDA) Took " << timer_seconds << " Seconds.\n";
return 0;
}위 변경된 코드를 컴파일해서 실행하면 아래 그림 1과 같은 결과 이미지를 확인 할 수 있다. 모든 코드는 출처 3에서 다운로드가 가능하다.

성능 측정 결과
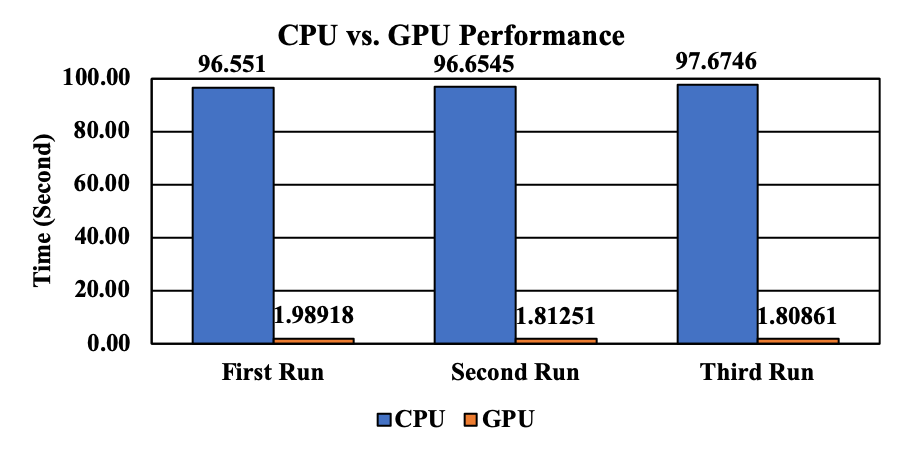
그림 2는 CPU/GPU 성능을 비교한 결과이다. GPU는 CPU 대비 대략 51배 정도 빠른 성능을 보인다. 앞 장에서 대략 70배 정도 성능 차이가 발생했다. 그렇기 때문에 오히려 성능 차이가 줄어든 것처럼 보인다. 하지만, 실제 시간 차이로 할 경우 GPU가 95초 이상 빨리 동일한 계산을 수행하는 것을 알 수 있다.
출처
- https://devblogs.nvidia.com/accelerated-ray-tracing-cuda/
- http://www.realtimerendering.com/raytracing/Ray%20Tracing%20in%20a%20Weekend.pdf
- https://github.com/mkblog-cokr/CudaRTSeries