이동 평균(Moving Average: MA)을 계산하기 위해서는 주어진 기준점에서 정해진 MA Window 크기(개수)만큼 수를 더해서 Window 크기로 나누기를 해주면 된다.
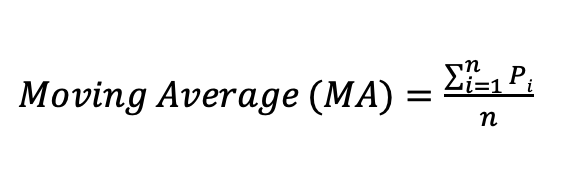
그림 1은 MA 계산을 하기 위한 식이다. C/C++을 사용해서 특정 Array의 첫 번째 Index의 Moving Average를 구한다면 MA Window 크기(개수)만큼 숫자를 더해서 MA 값을 구한다 (편의상 나누기 연산을 수행하지 않았다). 다음 Index의 MA 값을 구할 때는 앞에서 구한 값에서 제일 처음에 더한 값을 빼는 연산을 수행한다. 그리고 다음으로 속하게 되는 Pi 값을 더해주면 된다.
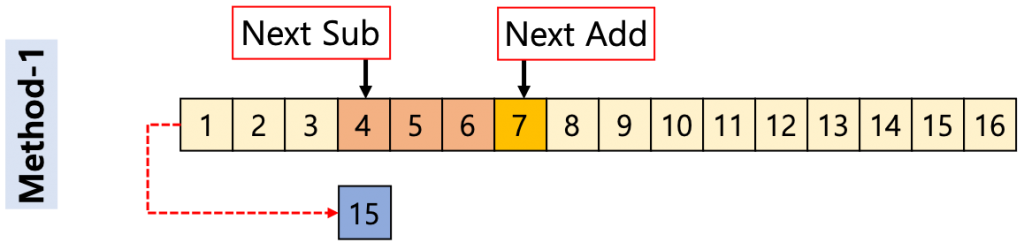
그림 2는 앞에서 설명한 방법을 표현한 그림이다. MA Window 사이즈에 따라 제일 앞에 값을 빼주는 위치의 Index와 더해주는 Array Index 값만 달라진다.
AVX-512를 사용해서 앞에서 설명한 MA Algorithm을 최적화해보고 싶어서 2가지 정도 다른 방식으로 코드를 구현해 보았다. 하나는 AVX-512 크기만큼 Array 값을 Loading해서 MA Window 크기만큼 무작정 더하는 방법이다.
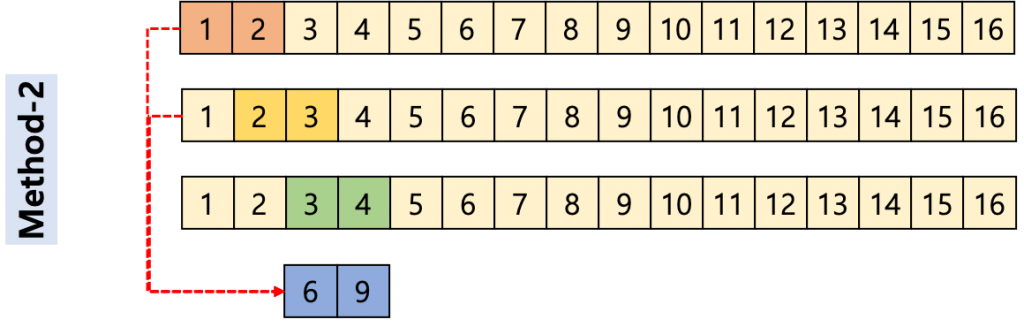
그림 3은 AVX-512를 사용해서 MA를 계산하는 방법을 묘사한 그림이다. 예를 들어서 AVX-512의 크기가 2개의 Integer를 계산할 수 있다고 가정하고, MA Window Size가 3인 경우 2개의 값을 3번 Loading 해서 더하는 작업을 수행하면 된다. AVX-512의 크기가 2개의 Integer를 계산할 수 있기 때문에 한 번에 2개의 MA 값을 계산 할 수 있다. 이 방법은 MA Window 크기에 따라 성능 차이가 크게 발생한다.
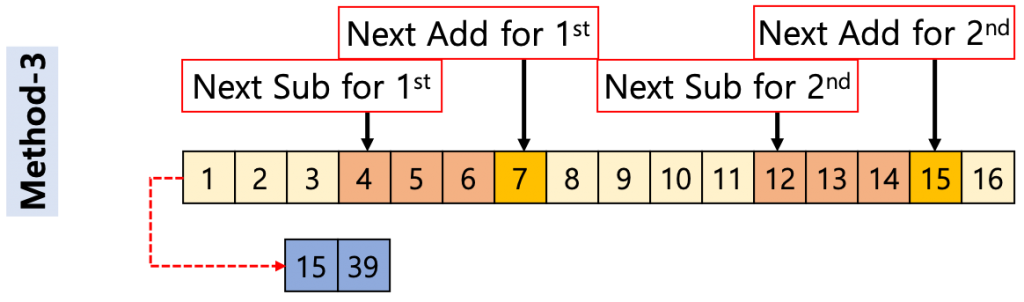
그림 4는 AVX-512를 사용해서 MA를 계산하는 다른 방법을 묘사한 그림이다. 이 방법은 MA 연산을 여러 위치에서 동시에 수행한다. 일정한 거리(Offset)를 두고 Method-1과 같은 방식으로 연산을 수행한다고 생각하면 된다. 예를 들어 AVX-512의 크기가 2개의 Integer 연산을 수행할 수 있으면 한 개는 1번, 다른 한 개는 8번부터 MA 연산을 수행하는 방법이다.
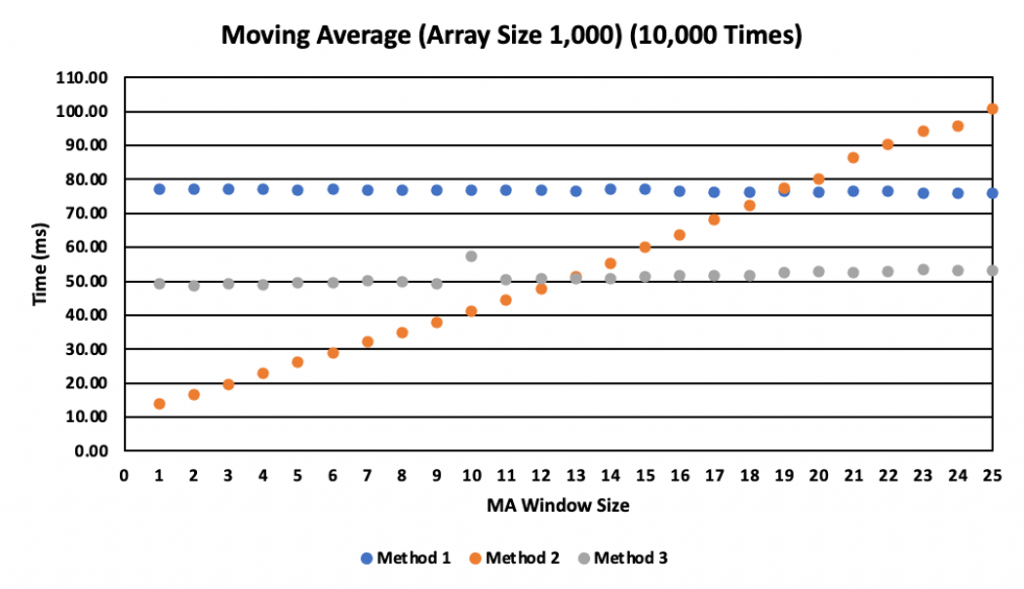
그림 5는 위 3가지 MA 구현 방식의 성능을 측정한 결과이다. Array Size는 1,000으로 고정하고, MA Window 사이즈를 1 ~ 25까지 변경해가면서 측정한 결과이다. 동일한 연산을 10,000번씩 수행하였다. 아래는 위 결과를 측정한 컴퓨터의 대략적인 실험 환경이다.
- CPU: i9-10920X
- OS: Centos 8
- g++ Version: 8.3.1
- Compile Option: -O3 -march=native
AVX-512는 16개 32-Bits Integer 연산을 한 번에 수행할 수 있는 SIMD Vector 연산이다. 그래서 Matrix Multiplication (MM) 등의 계산을 Single Core 대비 상대적으로 빨리 수행 할 수 있다. MA 같은 경우 SIMD Vector에서 더 빠른 연산 방법을 잘 모르겠다. 그래서 위와 같이 2가지 방법으로 구현을 해보았다.
Method-2의 경우 MA Window 사이즈에 따라서 연산량이 증가하는 형태이다. 작은 MA Window 사이즈의 경우 Method-1 (Single Thread) 대비 1/7시간에 연산을 마무리 할 수 있다. 하지만, MA Window 크기가 20을 넘어가는 순간부터 오히려 더 많은 시간이 걸린다.
반대로 Method-1, Method-3의 경우 MA Window 크기에 따른 성능 차이가 거의 발생하지 않는다. 그 이유는 MA Window 크기에 따른 연산량의 차이가 거의 없기 때문이다. Method-3의 경우 16개의 다른 부분에서 동시에 연산을 수행하지만 대략 30~40% 정도밖에 성능이 좋아지지 않는다.
여러 가지 이유가 있겠지만, AVX-512 Scatter/Gather Memory 연산 (Load 및 Store)이 느리기 때문인 것 같다. 추가로 AVX-512가 16개의 Integer 연산을 한 번에 수행할 수 있음에도 불구하고 최대 1/7 시간으로밖에 줄어들지 않는 이유는 CPU Clock 차이 때문일 수도 있다. 많이 알려진 사실이지만, AVX-512를 사용하는 경우 CPU Clock이 내려가는 현상이 확인된다고 한다 (출처 2).
개인적으로 궁금해서 Moving Average 연산을 AVX-512 코드로 작성해서 성능을 측정해보았다. 더 나은 방법이 있을 수도 있으나, 아직 찾지 못하였다. 혹시 더 나은 계산 방법을 찾게 되면 측정한 결과를 업데이트할 예정이다.
아래 코드는 위에 설명한 방법을 구현한 코드이다.
코드 1: MA 연산 코드
/*
* =====================================================================================
*
* Filename: main.cpp
*
* Description: Test for moving average
*
* Version: 1.0
* Created: 11/21/20 11:52:58
* Revision: none
* Compiler: g++
*
* Author: MKBlog (MK), mkblog.co.kr@gmail.com
* Organization: MKBlog
*
* =====================================================================================
*/
#include <immintrin.h>
#include <stdlib.h>
#include <time.h>
#include <cmath>
#include <iostream>
#include "mkClockMeasure.h"
const int MaxSize = 1000;
const int MaxIter = 10000;
const int AVXSIZE = 16;
using namespace std;
int randomNum[MaxSize];
int singleOutput[MaxSize];
int firstAvxOutput[MaxSize];
int secondAvxOutput[MaxSize];
static int maSize;
void genRandNumInput(){
int maxNum = 1 << 16 - 1;
for (int i = 0; i < MaxSize; i++) {
int rNum = rand() % maxNum;
randomNum[i] = (int)rNum;
}
}
void cpuMovingAvg(){
int tSum = 0;
for(int i = 0; i < maSize - 1; i++){
tSum += randomNum[i];
}
for(int i = 0; i < MaxSize - maSize; i++){
int lIdx = maSize - 1 + i;
tSum += randomNum[lIdx];
singleOutput[i] = tSum;
tSum -= randomNum[i];
}
}
union Int32Array {
__m512i v;
__m256i avx2[2];
int a[16];
};
void avxFirstMovingAverage(){
Int32Array constMaSize;
const int totalRun = MaxSize - maSize;
for(int i = 0; i < totalRun; i += AVXSIZE){
Int32Array tSum;
tSum.v = _mm512_setzero_si512();
__mmask16 tMask = (totalRun - i) > AVXSIZE ? 0xFFFF : (1 << (totalRun - i)) - 1;
for(int j = 0; j < maSize; j++){
Int32Array lValue;
lValue.v = _mm512_maskz_loadu_epi32(tMask, &randomNum[i + j]);
tSum.v = _mm512_add_epi32(lValue.v, tSum.v);
}
_mm512_mask_storeu_epi32(&firstAvxOutput[i], tMask, tSum.v);
}
}
void avxSecondMovingAverage(){
Int32Array constMaSize;
int distance[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
const int totalRun = MaxSize - maSize;
const int offset = ceil((float)totalRun / AVXSIZE);
Int32Array tDistance, tOffset, tSum, lValue;
tDistance.v = _mm512_loadu_si512(distance);
tOffset.v = _mm512_set1_epi32(offset);
tDistance.v = _mm512_mullo_epi32(tDistance.v, tOffset.v);
tSum.v = _mm512_setzero_si512();
for(int i = 0; i < maSize - 1; i++){
lValue.v = _mm512_i32gather_epi32(tDistance.v, &randomNum[i], 4);
tSum.v = _mm512_add_epi32(tSum.v, lValue.v);
}
for(int i = 0; i < offset; i++){
__mmask16 tMask = 0xFFFF;
if(tDistance.a[15] + i > totalRun){
tMask = 0x7FFF;
}
lValue.v = _mm512_mask_i32gather_epi32(lValue.v, tMask, tDistance.v, &randomNum[i + maSize - 1], 4);
tSum.v = _mm512_add_epi32(tSum.v, lValue.v);
_mm512_mask_i32scatter_epi32(&secondAvxOutput[i], tMask, tDistance.v, tSum.v, 4);
lValue.v = _mm512_i32gather_epi32(tDistance.v, &randomNum[i], 4);
tSum.v = _mm512_sub_epi32(tSum.v, lValue.v);
}
}
bool compareAllOutput(){
bool check = true;
for(int i = 0; i < MaxSize - maSize; i++){
if(singleOutput[i] != firstAvxOutput[i] || singleOutput[i] != secondAvxOutput[i]){
cout << "(NOT MATCH) " << i << " : " << singleOutput[i] << " != " << firstAvxOutput[i] << " != "
<< secondAvxOutput[i] << endl;
check = false;
}
}
return check;
}
int main(){
srand(time(NULL));
for(int i = 1; i < 30; i++){
maSize = i;
for(int tc = 0; tc < MaxIter; tc++){
genRandNumInput();
avxSecondMovingAverage();
avxFirstMovingAverage();
cpuMovingAvg();
if(!compareAllOutput()){
return 0;
}
}
}
return 0;
}출처
- https://www.econowide.com/3544
- https://travisdowns.github.io/blog/2020/08/19/icl-avx512-freq.html
좋은 정보 감사합니다.